Probability distributions
This chapter will focus on the problem of density estimation, which consists in finding / estimating the probability distribution from independent and identically distributed datapoints drawn from . There are two main ways of doing that: the first way is to use parametric density estimation, where you choose one known parametric distribution (e.g., Gaussian) and try to get the right parameters that fit the data. This method assumes that the parametric distribution we use it's suitable for the data, which is not always the case. Another way of doing that is using non-parametric density estimation techniques (e.g., histograms, nn, kernels).
Bernoulli experiment
Suppose we have a data set of i.i.d. observed values of . We can estimate the parameter from the sample in a frequentist way, by maximizing the likelihood (or the log-likelihood):
To find , let's set the log-likelihood derivative w.r.t. to 0:
Since then:
is estimated from the sample mean. In this case, the sample mean is an example of sufficient statistic for the model, i.e. calculating other statistics from the sample will not add more information than that.
Binomial distribution
Sticking with the coin flips example, the binomial distribution models the probability of obtaining heads out of total coin flips:
Where represents all the possible ways of obtaining heads out of coin flips. The mean and variance of a binomial variabile can be estimated by knowning that for i.i.d events the mean of the sum is the sum of the mean, and the variance of the sum is the sum of the variances. Because then:
Beta distribution
Please read the estimating_parameters_using_a_bayesian_approach notebook. Some quick notes here:
and
Multinomial variables
It's a generalization of the Bernoulli distribution where a random variable has possible values instead of being binary. We can represent the variable as a -dimensional binary vector where only one component can be asserted:
The probability of each component to be asserted is regulated by a probability vector , so that basically . Since the vector represents a probability distribution, then:
The multinomial distribution of is given by:
And the expected values is . Let's consider a dataset of N independente observations, then the likelihood function is:
where .
If we want to find from by maximizing the (log) likelihood, we have to constrain that to be a probability distribution and therefore we can use the Lagrangian multiplier
Setting the derivative w.r.t. to zero we get . We can solve for the Lagrangian multiplier by replacing this result in the equation and then we get that and .
We can also consider the distribution of the quantities (Multinomial distribution) conditioned on the parameter and on the number of observations:
where
Short description of Lagrangian Multiplier utility taken from Quora: You are trying to maximize or minimize some function (distance to treasure), while keeping some other function fixed at a certain value (stay on the path). At this point, the gradient (the compass needle) must be parallel to the gradient (the arrows on the signs), but the two vectors will not generally have the same length. The test for whether or not they’re parallel is , where is whatever multiplier is needed to have them match; it will still only be able to be equal if they’re parallel (you can resize the compass needle however you want to make it match the sign arrow, but you have to be at a spot with the right direction).
Dirichlet distribution
While the beta distribution is a prior of the Bernoulli parameter , the Dirichlet distribution is a prior of the Multinomial probability vector . The definition is:
Where . Since the parameters are bounded to , then the distribution is confined to a simplex in the space.
By multiplying the likelihood function (which is the multinomial distribution) by the prior (which is a Dirichlet distribution) we get something that is proportional to the posterior . Assuming a conjugate prior, the posterior has the same form and hence we can derive the normalization constant by comparison with the dirichlet distribution definition. The posterior is defined as:
Gaussian distribution
Univariate Gaussian distribution:
Where and are the mean and variance of the population.
Multivariate Gaussian distribution:
Where is the dimensionality of , is the mean vector and is the covariance matrix.
Central Limit Theorem. Subject to certain mild conditions, the sum of a set of random variables, which is of course itself a random variable, has a distribution that becomes increasingly Gaussian as the number of terms in the sum increases.
Observation n.1 - The covariance matrix is always positive semi-definite. This means that the eigenvalues are non-negative.
Observation n.2 - To be well-defined, a Gaussian must have a positive definite covariance matrix, which means that all the eigenvalues are strictly positive. If the covariance matrix has one or more null eigenvalues (positive semi-definite), then the distribution is singular and is confined to a subspace of lower dimensionality.
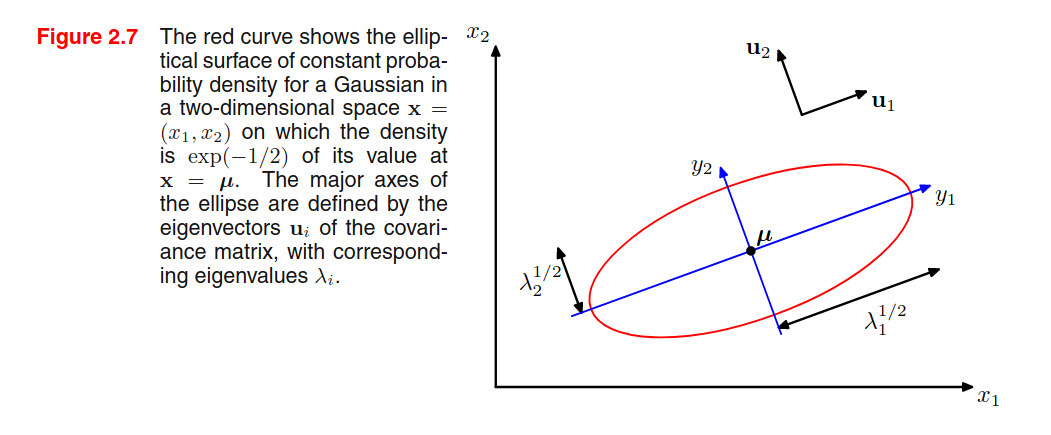
Observation n.3 - Given a 2D Gaussian distribution, we find that elements with constant density are distributed as ellipses, where the axis of the ellipse is given by the eigenvectors, and the length of the axis is proportional to the square root of the corresponding eigenvalue. The ellipse defined by the axis having a length equal to the square root of the eigenvalues, we find all the elements with a density of .
This is a hint on my preferred interpretation of eigenvectors and eigenvalues calculated from data: eigenvectors represent that capture most of the variability, and the corresponding eigenvalues are an indicator of the variability on that axis (see PCA).
Observation n.4 - A multivariate Gaussian can be decomposed as a product of multiple univariate Gaussians.
Observation n.5 - The book provides a formal proof to find that and .
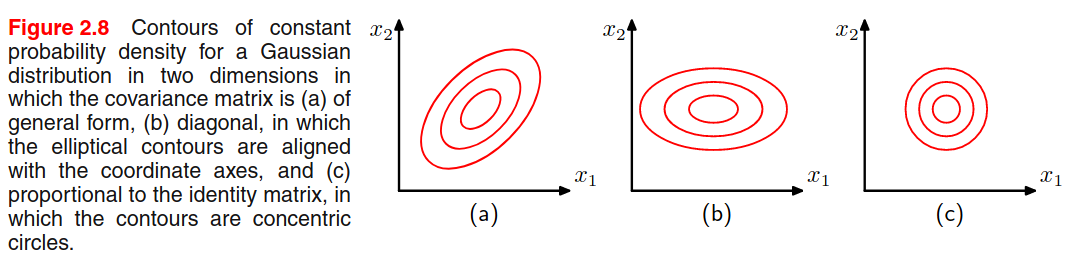
Observation n.6 - A general symmetric covariance matrix has independent parameters, and there are another independent parameters in , giving parameters in total. This means that the number of parameters grows quadratically with the dimension .
One way to reduce the number of parameters is to use restricted forms of the covariance matrix. For example, with a diagonal covariance matrix (figure b) we a linear dependency between parameters and dimensionality, but we explain the variability only from the features axis. Another possibility is to use the isotropic covariance (Figure c) where we have only one parameter, but we discard the variability along multiple axis. We have a trade-off between model complexity and flexibility that must be adressed based on the application.
Limitations of the Gaussian - Gaussian is unimodal (only 1 maximum) and thus is not good at representing multimodal data.
Conditional & Marginal Gaussian Distributions
Given a joint Gaussian distribution with (precision matrix) and
where and .
Then we have that the conditional distribution is
Note that is a linear function of .
where
And that the marginal distribution :
All the derivations focus on the quadratic relationship of the exponential factor to the and are detailed starting from page 85. The point is that the conditional and marginal distribution of a joint Gaussian distribution are again Gaussian distributions.
Given a marginal Gaussian distribution for and and a conditional Gaussian distribution for given in the form:
Where expresses the fact that the mean of the conditional distribution given is a linear function of , and is another precision matrix. The marginal distribution of and the conditional distribution of given are given by:
where
Maximum likelihood for the Gaussian
Let be a dataset of observation drawn independently from a multivariate Gaussian distribution. We can estimate the parameters by maximizing the log-likelihood:
By setting the derivative to zero, we can compute:
Where we calculate the two parameters in sequential steps since there's no dependency on when maximizing with respect to . By taking the expectation we see that:
We see that is a biased estimator, and we can correct it by:
Now is a correct extimator for the true covariance.
Student's t distribution
In order to estimate the precision of a Gaussian distribution by using a Bayesian approach, we can use the Gamma distribution as a prior: Then we can marginalize to obtain By performing a number of steps, we can say that this is a Student's t distribution: Where (precison) and (degrees of freedom). The precision of the t distribution doesn't correspond to the inverse of the variance!
The parameters can be estimated by Expectation-Maximization, and the result has the property of robustness: outliers does not severely affect the distribution.
The multivariate version of the t distribution is: and The statistics are
Exponential family
A distribution that is part of the exponential family can be represented as:
Where are the natural parameters of the distribution. The function ensures that the distribution is normalized:
The Bernoulli (), Multinomial () and Gaussian distributions are part of this family, and the PRML book proofs this at page 113.
If we want to estimate , we can do that by maximum-likelihood. Let's set the gradient of w.r.t. to 0:
(a) To understand the underlined expression, remember that the integration is w.r.t. , while the differentiation is w.r.t. , so we directly differentiate the content as the derivative of sums is the sum of derivatives.
(b) recall that , this means that
Point (c) is provided by the identity (chain rule).
We will use this result later on. Now suppose to have i.i.d. observations drawn from the exponential distribution . The likelihood function is given by:
Setting we get:
which can be solved to obtain . The solution depends on the data only through , which is called the sufficient statistic of the exponential distribution. For then ,
For each exponential distribution of the previous form, there exists a conjugate prior distribution over the parameters of the following form
Where is a normalization coefficient, is the same function presented in the exponential distribution, can be interpreted as a effective number of pseudo-observations in the prior, each of which has a value for the sufficient statistic given by .
Again - why do we need conjugate priors??
A prior which is conjugate to the likelihood produce a posterior that has the same functional form as the choosen prior. This allows to derive a closed-form expression for the posterior distribution (otherwise you need to compute the normalization coefficient by integration, YOU DON'T WANT TO DO THAT, RIGHT?)
Noninformative prior
If we have no prior information, we want a prior with minimal influence on the inference. We call such a prior a noninformative prior. The Bayes/Laplace postulate, stated about 200 years ago says the following:
The principle of insufficient reason. When nothing is known about in advance, let the prior be a uniform distribution, that is, let all possible outcomes of have the same probability.
One noninformative prior could be the uniform distribution, but there are two problems:
- If the parameter is unbounded, the prior distribution cannot be correctly normalized because the integral over diverges. In that case, we have an improper prior. In pratice, improper priors are used if the posterior is proper, i.e. is correctly normalized.
- The second problem is that if we perform a non-linear change of variable, then the resulting density will not be constant (recall the Jacobian multiplier).
Nonparametric Methods
The distribution we have seen are governed by parameters that are estimated from the data. This is called parametric approach to density modelling.
In this section we talk about nonparametric approaches to density estimation (only simple frequentist methods).
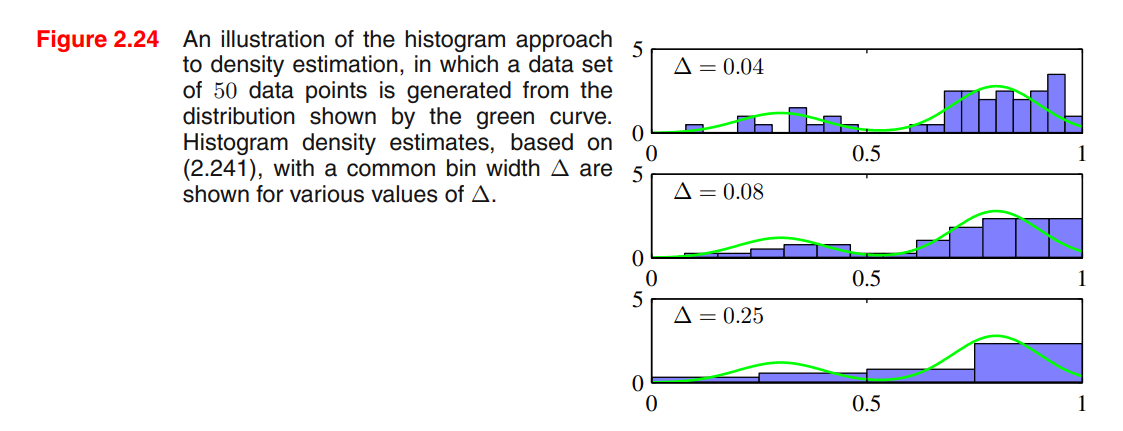
Consider a continuous variable , the simplest way to model that distribution is to partition observations of in different bins of width (often the same for every bin ), and then count the number of observation of falling in bin . To turn this count into a normalized probability density:
Problems:
- If we choose too small, the resulting distribution will be too spiky (i.e. will show structures that are not present in the real distribution)
- If we choose too big, the resulting distribution may fail to capture the structures of the real distribution
Advantages:
- Good visualization of the distribution
- The dataset can be discarded once the histogram is built
- Good setup if data points are arriving sequentially
Disvantages:
- The estimated density has discontinuities in the bin edges
- Does not scale with dimensionality (curse of dimensionality), the amount of data needed to work in high dimensional spaces is prohibitive.
Good ideas:
- To estimate probability density at a particular location, we should consider the data points that lie within some local neighbourhood of that point.