Linear models for classifications
4.1.3 Least squares for classification
Matrices legend.
Matrix Dimension
Consider a classification task with classes, let be a one-hot encoding target vector. Each class is described by its own linear model so that
By using vector notation, we can combine them together:
Where is a matrix such that the -th column is and .
Objective: to determine the parameters of by minimizing a sum-of-squares loss function.
Consider a training dataset and define two sparse matrices
- of dimension such that the -th row is the binary one-hot-encoded vector .
- of dimension such that the -th row is
The sum-of-squares loss function can be written as:
Question: why do we use the trace?
Set the derivative of w.r.t. to zero and obtain the following solution:
If we want to obtain the result without using too much matrix calculus we can do the following:
The discriminant function will be:
Problems with the discriminant function obtained through minimization of SSE:
- Sensible to outliers
- Bad performances since it estimates under assumption of Gaussian noise, which is clearly wrong when estimating a binary vector
An interesting property
Every target vector in the training set satisfies some linear constraint:
For some costants . The model prediction for any value of will satisfy the same constraint
If we use a one-hot-encoding scheme for , then components of will sum up to 1. However, this is not enough for considering a probability distribution since its components are no bound to .
4.1.4 Fisher's linear discriminant
Suppose we have 2 classes, the idea is to project the D-dimensional input to a scalar value and classify as class if and class otherwise.
The problem is that projecting the input from D dimensions to 1 dimension consists on a significant loss of information, and if the classes are well separated in the high-dimensional space, they can overlap in the 1-dimensional space. However, we can optimize in order to maximize the separation between classes in the 1-dimensional space.
One way to do this is to consider the class mean vectors:
And maximize
where . One problem is that we can make arbitrarly large by incrementing the magnitude of . This can be solved by constraining a fixed magnitude . To enforce this constraint during optimization, we can use Lagrange multipliers. We find that .
The problem with this simple approach is that it doesn't take the variance into account, and the datapoints in the 1-dimensional space may be overlapped (e.g., when their distribution has a strongly nondiagonal covariance). See the figure on the left below.
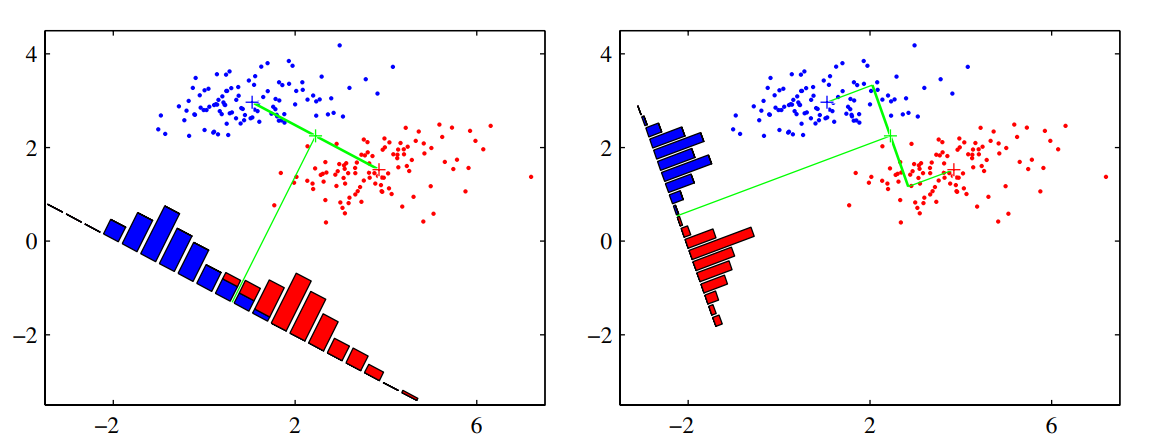
The discriminant function on the right is obtained using the Fisher linear discriminant, which introduce the variance in the objective to optimize.
Define the variance of class in the projected space as:
where . The total within-class variance for the whole dataset is simply . The fisher criterion to maximize is defined as the ratio of the between-class variance to the within-class variance:
We can rewrite the Fisher criterion in the following form to make the dependence on explicit:
Where is the between-class covariance matrix:
and is the total within-class covariance matrix:
By differentiation, we find that is maximized when
Since we only care about the direction of , we can drop the scalar factors and . Then we multiply both sides by and obtain the Fisher Linear Discriminant:
If the within-class variance is isotropic, so that is proportional to the unit matrix, then we find that is proportional to the difference of the class means.
The projection function is not really a discriminant, but we can construct a discriminant by choosing a threshold to classify the points.
Relation to least squares
For the two class problem, the Fisher criterion can be obtained as a special case of least squares.
Let be the total number of observations, the observations from class, and from class. Reparameterize the target values as:
- if
- if
Write the sum of squares error function:
By setting and , after some algebraic manipulations, we find:
where corresponds to the solution for the Fisher criteria, and we have also obtained an expression for the threshold , where is the mean of all the observation. For intermediate steps, check page 210.
Fisher discriminant for multiple classes
Suppose classes. Let , where . We need to project the observation to , and we can calculate each component as follows
Where . We can group for as columns of a matrix of dimension , and calculate the vector in one step as:
Let's define the within and between class covariances for the multi-class problem.
The within class covariance is:
The between class covariance is:
Now let's define the covariances but in the projected space of .
The within class covariance is:
The between class covariance is:
There exist different objective functions to maximize, but here we use the one from (Fukunaga, 1990), which is:
Rewriting with explicit dependence on :
Solution: the columns of the matrix that maximizes are the D' eigenvectors of the D' largest eigenvalues of the matrix .
Observation: Since the matrix resulting from an outer product of non-zero vector has always a rank of 1, since is composed by the sum of rank-1 matrices and since only of these matrices are independent, then as a rank at most equal to , and therefore there are at most non-zero eigenvalues. This means that we are unable to find more than linear features by this method (Fukunaga, 1990).
Right now we have only reduced the dimensionality of the data. Where is the discriminant function?
4.1.7 Perceptron
Find my notes about Perceptron here (in italian).
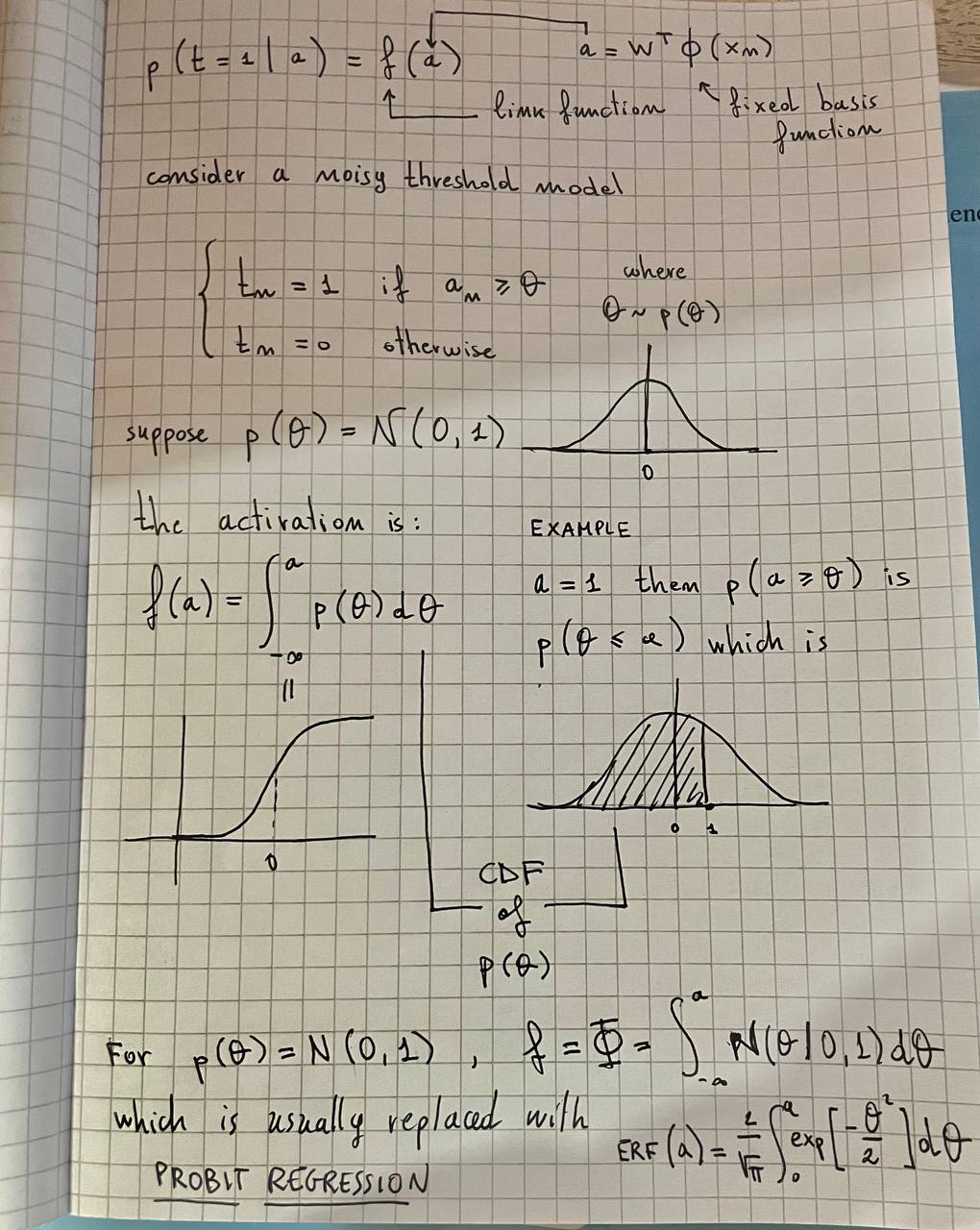
4.2 Probabilistic Generative Models
Consider the binary classification task. We want to compute the posterior probability :
Where is the sigmoid function, which has the property .
The inverse of the logistic sigmoid is given by the logit function:
It represents the log of the ratio of probabilities for the two classes.
For classes, we have:
where the quantities are defined as:
This function, called normalized exponential, is also known as the softmax function.
Continuous inputs
Assume that
- is continuous
- Class conditional densities are Gaussian
- They share the same covariance matrix
Consider the binary classification task. From the results above, we have:
Where:
Hence we have that the argument of the activation function is linear w.r.t. the input .
Since the decision boundaries are defined as the areas where is constant, and since this depends only on the argument of the sigmoid, which is linear w.r.t. , therefore the decision boundaries are also linear w.r.t. .
Changing the prior probabilities will only shift the decision boundaries, since they appear only in the bias parameter .
For classes, we have
where
Relaxing the assumption of a shared covariance matrix and considering a different covariance matrix for each class will result in a quadratic dependency w.r.t. of w.r.t. (also called quadratic discriminant).
Maximum likelihood solutions
See the derivations at page 220. Suppose we have samples and their binary class labels , where , suppose samples belong to class and to class . If we condire Gaussian class conditional densities and with shared covariance matrix , then the maximum likelihood likelihood solutions are:
- centroid of samples from class
- centroid of samples from class
- sum of covariance matrices of and weighted by the priors.
Probabilistic Discriminative Models
Probit regression