Reti neurali
1. Introduzione
1.1 Reti neurali biologiche
I neuroni sono le più importanti cellule del sistema nervoso. Le connessioni sinaptiche (o sinapsi) agiscono come porte di collegamento per il passaggio dell'informazione tra neuroni. I dendriti sono fibre minori che si ramificano a partire dal corpo cellulare del neurone (detto soma). Attraverso le sinapsi, i dendriti raccolgono input da neuroni afferenti e li propagano verso il soma. L'assone è la fibra principale che parte dal soma e si allontana da esso per portare ad altri neuroni (anche distanti) l'output.
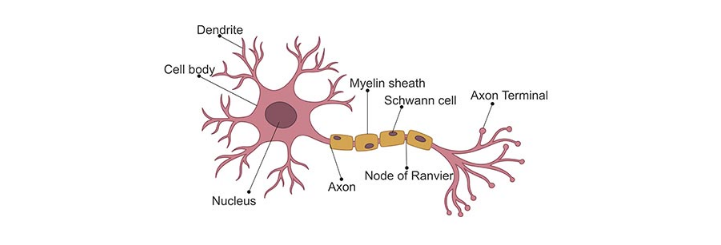
Il passaggio delle informazioni attraverso le sinapsi avviene con processi elettro-chimici: il neurone presinaptico libera delle sostanze, chiamate neurotrasmettitori, che attraversano il breve gap sinaptico e sono captati da appositi recettori, detti canali ionici, sulla membrana del neurone postsinaptico. L'ingresso di ioni attraverso i canali ionici determina la formazione di una differenza di potenziale tra il corpo del neurone postsinaptico e l'esterno. Quando questo potenziale supera una certa soglia, detta di attivazione, si produce uno spike o impulso: il neurone propaga un breve segnale elettrico detto potenziale d'azione lungo il proprio assone: questo potenziale determina il rilascio di neurotrasmettitori dalle sinapsi dell'assone.
Il reweighting delle sinapsi, ovvero la modifica della loro efficacia di trasmissione, è direttamente collegato ai processi di apprendimento e memoria in accordo con la regola di Hebb.
Hebbian Rule: se due neuroni, tra loro connessi da una o più sinapsi, sono ripetutamente attivati simultaneamente allora le sinapsi che li connettono sono rinforzate.
Il cervello umano contiene circa 100 miliardi di neuroni, ciascuno dei quali connesso con circa altri 1000 neuroni ( sinapsi). La corteccia celebrale (sede delle funzioni nobili del cervello umano) è uno strato laminare continuo di 2-4 mm, una sorta di lenzuolo che avvolge il nostro cervello formando numerose circonvoluzioni per acquisire maggiore superficie. Sebbene i neuroni siano disposti in modo ordinato in livelli consecutivi, l'intreccio di dendriti e assoni ricorda una foresta fitta ed impenetrabile.
1.2 Reti neurali artificiali
Il primo modello di neurone artificiale fu progettato da McCulloch e Pitts: gli input e gli output erano binari ed erano in grado di eseguire delle computazioni logiche.
Un neurone artificiale moderno prende in ingresso input , pesati rispettivamente con pesi che rappresentano l'efficacia delle connessioni sinaptiche dei dendriti. Tali valori varieranno durante il processo di apprendimento. Esiste un ulteriore peso, detto costante di bias, che si considera collegato ad un input fittizio con valore costante 1, questo peso è utile per tarare il punto di lavoro ottimale del neurone.
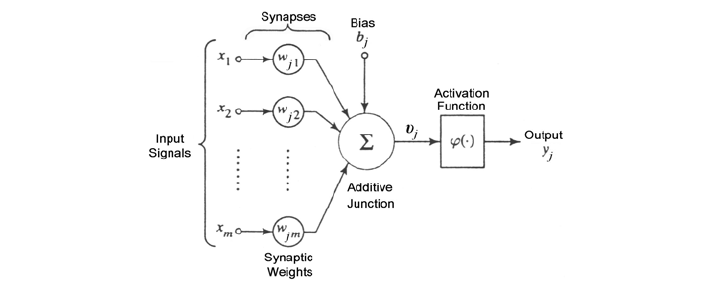
Il neurone somma i prodotti tra gli input ed i corrispettivi pesi (compresa la costante di bias) e produce un valore . Dopodiché, sulla base di una funzione di attivazione a cui viene passato il valore , produce un valore di output.
1.2.1 Layer
Le reti neurali sono composte da gruppi di neuroni artificiali organizzati in livelli o layer. Tipicamente sono presenti un layer di input, un layer di output, ed uno o più layer intermedi o nascosti (hidden). Ogni layer contiene uno o più neuroni.
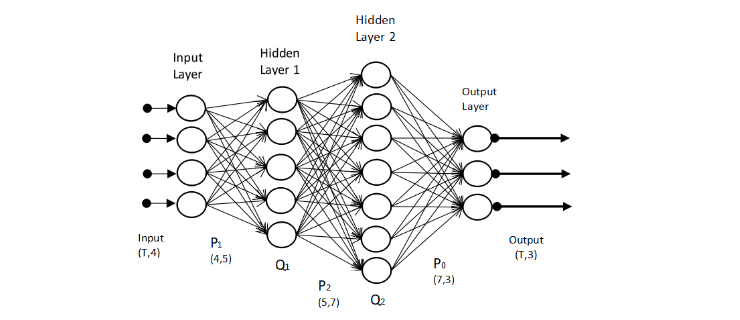
Il layer di input è costituito da un vettore di valori . Gli hidden layer sono costituiti da uno o più nodi che prendono in input uno o più valori provenienti dal layer precedente. Ogni nodo dell'hidden layer produrrà un output che verrà passato ad uno o più nodi del layer successivo. Il layer di output è costituito da uno o più nodi che restituiscono in output un valore. Il termine deep neural network indica una rete formata da molti layer nascosti.
1.2.2 Tensori
Nel contesto delle reti neurali, un tensore è un array -dimensionale, ovvero una generalizzazione di un vettore o di una matrice. Nel modello più generale di rete neurale sia l'input che l'output di un nodo della rete può essere un tensore. I nodi di un layer possono essere organizzati e disposti a formare una matrice (come nelle convolutional networks) o un tensore. Nel primo caso ritroviamo il tensore al livello dei dati, mentre nel secondo lo ritroviamo come disposizione dei nodi della rete.
1.2.3 Connessioni tra layer
Una rete neurale in cui ogni nodo di un certo layer riceve tutti gli output del layer precedente è detta densa. In questo caso si parla di layer totalmente connessi. Altre tipologie di connessioni tra layer sono possibili:
- Connessione random: fissato , ogni nodo riceve output solamente da nodi (generalmente casuali) del precedente layer.
- Connessione pooled: i nodi di un layer sono partizionati in cluster. Il layer successivo, chiamato pooled layer, sarà formato da nodi, uno per ogni cluster. Il nodo associato al cluster riceverà tutti e soli gli output dei nodi del layer precedente appartenenti al cluster .
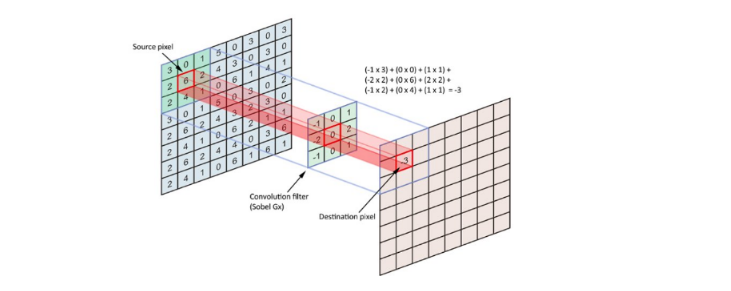
- Connessione convolutional: i nodi di ogni layer sono visti come se fossero disposti su una griglia. Il nodo di coordinate riceve tutti e soli gli input dei nodi del layer precedente che si trovano in una regione piccola della griglia intorno al punto (vediamo una immagine che rappresenti cosa si intende per convoluzione).
1.3 Explanable AI
La rete neurale si presenta come un modello black-box: un osservatore esterno vede l'output prodotto dal modello a partire da un input, ma il modello non è in grado di giustificare il risultato ottenuto, ovvero non è in grado di spiegare il procedimento logico per cui si arriva a produrre quel risultato. Il termine Explanable AI indica una serie di tecniche a supporto di modelli di intelligenza artificiale per far sì che un risultato prodotto da tali modelli possa essere compreso da un essere umano. Tali tecniche sono molto importanti in ambito medico, nella guida autonoma, nella computer vision, etc.
1.4 Progettare una rete neurale
La costruzione di una rete neurale è fondamentale per ottenere un modello di machine learning in grado di classificare o predire accuratamente. Per prima cosa bisogna definire la struttura della rete:
- Quanti hidden layer definire?
- Quanti nodi deve contenere ciascun layer?
- Come connettere i nodi di layer consecutivi?
- Quale funzione di attivazione scegliere per ogni layer?
Una volta definita la struttura, il modello deve essere addestrato su un training set al fine di trovare i valori ottimali dei pesi degli input ricevuti da ogni nodo della rete neurale in ogni layer. Per fare ciò occorre definire una funzione di costo globale , detta funzione loss, e trovare i pesi che la minimizzino. Le due ulteriori domande da porsi sono:
- Come deve essere organizzato il training set? Da quanti elementi?
- Quale funzione loss scegliere?
La progettazione di una rete neurale è per lo più uno studio empirico, fatto di tentativi. Le linee guida per la progettazione sono le seguenti:
- Una rete neurale con meno layer richiede tempi di addestramento ed esecuzione minori.
- Una rete neurale con più layer permette di risolvere problemi decisionali più complessi.
- Troppi layer producono un modello troppo complesso con un concreto rischio di overfitting.
- Tre layer sono spesso buoni nella pratica.
- Definire molti nodi in un hidden layer permette di identificare pattern più complessi nei dati.
- Per prevenire l'overfitting è conveniente partire da un basso numero di nodi ed aumentarlo gradualmente, monitorando le performance del modello.
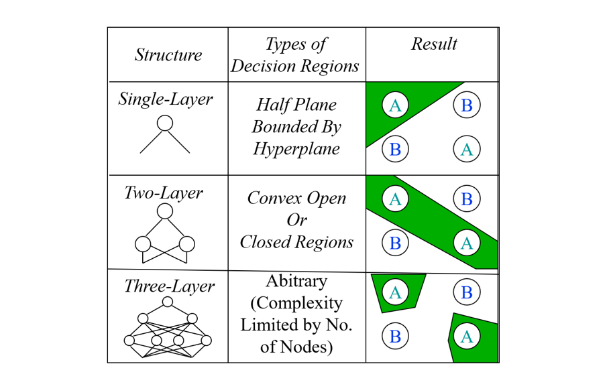
2. Funzioni di attivazione
2.1 Definizione formale
Sia il vettore dei valori ricevuti da un nodo, il vettore dei pesi e la costante di bias. La funzione di attivazione di un nodo è la funzione che determina la risposta prodotta a partire da: Tutti i nodi di un layer hanno la stessa funzione di attivazione.

2.2 Proprietà desiderate
La scelta della funzione di attivazione si lega al metodo scelto per ottimizzare i pesi della rete basato sulla minimizzazione della funzione loss. Il metodo di minimizzazione più popolare è quello della discesa del gradiente (gradient descent). Affinché il gradient descend lavori al meglio, la funzione di attivazione deve avere delle proprietà desiderate:
- La funzione deve essere continua e differenziabile in ogni punto (o quasi).
- La derivata della funzione non deve saturare, ovvero tendere a zero nel proprio dominio: questo potrebbe portare ad uno stallo nel processo di ricerca dei pesi ottimali.
- La derivata della funzione non deve esplodere, ovvero tendere all'infinito nel proprio dominio: questo potrebbe portare instabilità numerica nel processo di ricerca dei pesi ottimali.
2.3 Unit step function
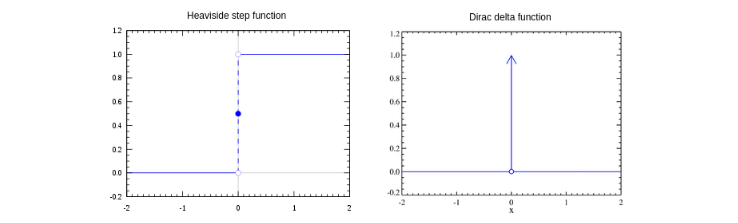
La più semplice funzione di attivazione è la funzione step, chiamata anche heaviside step o unit step function. Il nodo che usa la funzione step restituisce valori binari e viene per questo chiamato percettrone. La funzione è definita come segue:
La derivata della funzione unit step function è notoriamente la funzione Delta di Dirac . Quest'ultima satura a 0 per ed esplode ad quando , per cui non rispetta delle proprietà desiderate e non è una buona scelta per una deep neural network.
Può essere utilizzata per costruire un classificatore discriminativo binario o multi-classe. Il Perceptron è un esempio di classificatore binario, con un solo nodo nell'output layer che restituisce 1 se un oggetto è di una classe, 0 se è dell'altra. Per ottenere un classificatore discriminativo multi-classe occorre creare nell'output layer un percettrone per ogni classe da riconoscere. La rete neurale produrrà in output un vettore binario con un solo valore pari ad 1, che determinerà la classe finale, e tutti gli altri posti a 0. Uno o più hidden layer sono necessari per catturare pattern specifici di ciascuna classe al fine di guidare l'output layer ad identificare la classe corretta.
2.4 Funzione logistica
La funzione logistica, affrontata nel capitolo sulla predizione, appartiene alla classe delle funzioni sigmoidee, aventi cioé una curva a forma di . La definizione è la seguente: La funzione assume valore per ; quando la funzione , mentre quando la funzione .
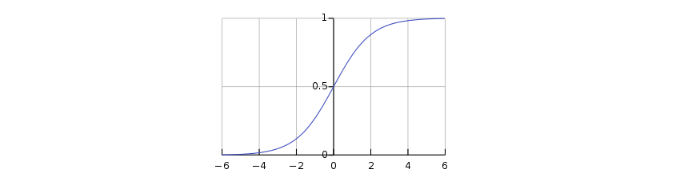
Dal grafico osserviamo la somiglianza con la funzione unit-step. La differenza chiave sta nell'approccio della funzione tendendo allo zero: l'andamento è graduale anziché diretto. Dato un vettore di valori , la funzione logistica è applicata su ognuna delle componenti: Se indichiamo con , allora la derivata della funzione logistica è: Allontanandosi dal punto in ambo le direzioni, la derivata tende a 0 e quindi la funzione tende a saturare (prop. 1). A differenza della unit-step function, la funzione logistica restituisce valori tra 0 ed 1 (prop. 2). Nel contesto della classificazione ciò implica che la funzione logistica può essere utilizzata nel layer di output per restituire la probabilità di appartenenza a ciascuna classe.
2.5 Tangente iperbolica
Anche la tangente iperbolica appartiene alla classe delle funzioni sigmoidee ed è definita come:
La tangente iperbolica risulta legata alla funzione logistica dalla seguente relazione:
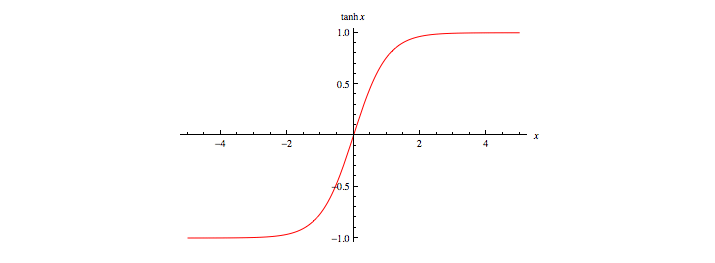
In altre parole, la tangente iperbolica è una versione scalata e traslata della funzione logistica. Essa ha valori compresi tra -1 ed 1 ed è simmetrica rispetto all'asse . Gode delle stesse proprietà enunciate per la funzione logistica.
2.6 Funzione softmax
A differenza delle funzioni sigmoidee, la funzione softmax non opera sulla singola componente del vettore, ma sull'intero vettore. Sia un vettore di valori, la funzione softmax è definita come dove il generico è calcolato come segue: La funzione ha valori in come la funzione logistica. La somma dei valori calcolati su ogni componente del vettore è 1, dunque è una distribuzione di probabilità. Grazie all'esponenziale, le componenti del vettore con valori più alti ricevono valori molto più alti rispetto alle altre. In particolare se c'è una componente con un valore significativamente più alto rispetto a tutti gli altri, a questa componente corrisponderà un valore vicino ad 1, mentre alle restanti un valore prossimo allo 0. La softmax ha problemi di saturazione, che possono essere aggirati utilizzando come funzione costo l'entropia incrociata.
Il denominatore della funzione softmax coinvolge una somma di esponenziazioni. Quando i valori variano in un range molto ampio, le loro esponenziazioni finiscono per variare in un range esponenzialmente più ampio, che coinvolge valori molto piccoli e molto grandi. Sommare valori molto piccoli e molto grandi può portare a problemi di accuratezza nel calcolo svolto da una macchina.
Osserviamo che per una qualsiasi costante : Se fissiamo , allora ogni esponente avrà come potenza un valore e quindi le somme avranno addendi compresi nell'intervallo [0, 1], il che porta ad un calcolo più accurato.
2.7 Rectified Linear Unit (ReLU)
La funzione ReLU prende spunto dai raddrizzatori a singola semionda (half-wave rectifiers) usati in elettronica per trasformare un segnale alternato in un segnale unidirezionale (sempre positivo o sempre negativo) facendo passare solo semionde positive. È formalmente definita come segue: Rappresentabile con il seguente grafico:
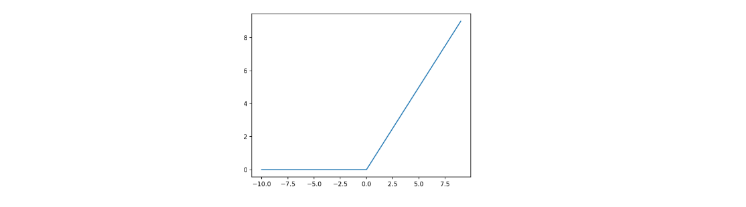
La funzione ReLU non satura mai per valori di positivi. Nella pratica, le reti neurali che utilizzano ReLU offrono uno speed-up significativo nella fase di training rispetto alle funzioni sigmoidee. Sia il calcolo della funzione che della sua derivata sono molto semplici e veloci da effettuare poiché non è richiesta l'esponenziazione. ReLU soffre di problemi di saturazione della sua derivata quando è negativo.
2.8 Exponential Linear Unit (ELU)
Un miglioramento per ReLU che attenua il problema della saturazione per consiste nel definire una variante chiamata ELU (Exponential Linear Unit), definita come segue: Dove è un iper-parametro tenuto fisso durante il learning dei pesi. Il processo di learning viene ripetuto con diversi valori di per trovare il valore che permette di ottenere performance migliori.
3. Funzioni Loss
La loss function, o funzione costo, è quella funzione utilizzata nel processo di learning dei pesi del modello. Essa quantifica la differenza tra le predizioni di un modello e i valori corretti di output osservati nel training set, quindi l'errore medio di predizione tra valori predetti e valori reali. I pesi ottimali sono quelli che minimizzano la funzione loss. Distinguiamo due tipologie di funzioni loss in base al problema che affronta la rete neurale:
- Regression loss nei problemi di regressione, da in output uno scalare o un vettore di valori reali
- Classification loss nei problemi di classificazione, da in output una distribuzione di probabilità, con valori che indicano la probabilità di appartenenza ad una classe.
3.1 Regression loss
Sia l'input, l'output reale ed il valore predetto dalla rete neurale. Le prime due regression loss function più comuni sono la squared error loss: e la Huber loss: dove è una costante. La Huber loss è in parte definita come la squared error loss (per valori minori di ). Supponendo , osserviamo le due funzioni a confronto in funzione al valore ():
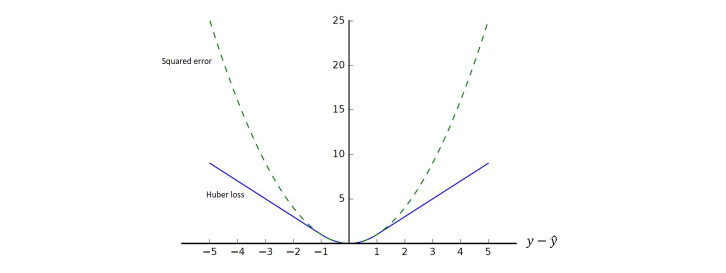
La Huber loss penalizza di meno le differenze tra i valori reali e quelli predetti, mentre la squared error loss tende all'infinito anche con errori relativamente piccoli. La variante Huber loss protegge il processo di learning nel caso di outlier, dove la squared error segnalerebbe un errore molto grande.
3.1.1 Mean Squared Error (MSE)
Le funzioni squared error ed Huber loss funzionano per un solo dato. Nel caso volessimo calcolare l'errore su un insieme di dati su cui è stata effettuata una predizione, dovremmo affidarci ad altri metodi.
Sia il training set e l'insieme di coppie formate dai valori di input e dai rispettivi output predetti dalla rete. Definiamo il Mean Squared Error come la misura dell'errore quadratico medio: La radice quadrata del MSE è definita Root Mean Square Error (RMSE). Nella pratica è preferibile il MSE perché il calcolo della derivata (ai fini dell'utilizzo del gradient descent) è più semplice. A causa del termine al quadrato, il MSE è molto sensibile agli outliers. Pochi outlier possono incrementare di molto il valore MSE, compromettendo il learning. Per attenuare questo effetto, conviene calcolare l'errore medio utilizzando la Huber Loss.
3.1.2 Regression loss con vettori
Nel caso in cui l'output è un vettore di valori anziché uno scalare, si sostituisce nel calcolo della squared loss, della Huber loss e del MSE la norma della differenza tra i vettori reale e predetto al posto della differenza tra i valori scalari.
3.2 Classification loss
Poniamoci in un generale problema di classificazione con classi . Supponiamo di avere un training set dove è il vettore degli input e è una distribuzione di probabilità. La componente del vettore indica la probabilità che appartenga alla classe .
Supponiamo che la rete neurale sia progettata, ad esempio attraverso una softmax, per produrre in output una distribuzione di probabilità , dove indica la probabilità predetta dal modello che sia di classe . Le funzioni di classification loss quantificano la distanza tra le distribuzioni di probabilità e .
3.2.1 Entropia
Supponiamo di avere un alfabeto di simboli. Si vuole trasmettere un messaggio utilizzando questi simboli attraverso un canale di informazione. Sia una distribuzione di probabilità. Supponiamo che in ogni punto del messaggio la probabilità di osservare l'-esimo simbolo sia .
Il teorema di Shannon afferma che, in un sistema di codifica ottimale, il numero medio di bit per simbolo necessari per codificare il messaggio è dato dall'entropia : Il termine indica il numero di bit necessari a rappresentare l'-esimo simbolo usando lo schema di codifica ottimale. Qualunque altro schema utilizza in media più bit, dunque è sub-ottimale.
3.2.2 Entropia incrociata
Nella teoria dell'informazione, l'entropia incrociata (o cross-entropy) tra due distribuzioni di probabilità e , relative allo stesso insieme di eventi, misura il numero medio di bit necessari ad identificare un evento estratto dall'insieme nel caso sia utilizzato uno schema alternativo anziché la vera distribuzione .
Supponiamo di cambiare lo schema di codifica, usando una diversa distribuzione di probabilità . Con questo nuovo schema occorrono bit per rappresentare l'-esimo simbolo. Quanti bit per simbolo occorrono in media se usiamo questo schema di codifica sub-ottimale? Dalla definizione di entropia incrociata possiamo calcolarlo come segue:
3.2.3 Divergenza di Kullback-Leibler
In generale sappiamo che poiché è sub-ottimale, mentre è ottimale. La differenza tra e , chiamata Divergenza di Kullback-Leibler (KL), misura il numero medio di bit in più che occorrono per ogni simbolo: Minimizzare la divergenza di equivale a minimizzare l'entropia incrociata. Nella pratica si utilizza l'entropia incrociata come funzione loss. Essa è la più comune funzione di classification loss ed è spesso accoppiata (es. in TensorFlow) con la funzione di attivazione softmax in un'unica funzione numericamente più stabile, la cui derivata è semplice da calcolare.
3.2.4 Binary Cross-Entropy Loss
Come abbiamo già detto, la cross-entropy può essere utilizzata per definire una funzione loss. Poniamoci nel caso binario in cui le sole due classi di appartenenza sono . Sia la reale probabilità che la -esima tupla appartenga alla classe 1. Sia la probabilità stimata dall'algoritmo che la -esima tupla appartenga alla classe 1.
Utilizziamo una funzione di attivazione che dia in output delle probabilità, come la softmax. Data una tupla , la softmax ci comunicherà che con probabilità la tupla apparterrà alla classe 1, mentre con probabilità la tupla apparterrà alla classe 0.
Avendo fissato le notazioni e è possibile utilizzare la cross-entropy per misurare la dissimilarità tra e : Utilizziamo la cross-entropy come loss function per una tupla ed ipotizziamo di voler calcolare la cross-entropy media per tutte le tuple del training set: Tale funzione loss è chiamata binary cross-entropy loss.
4. Training di una rete neurale
Il processo di training consiste nel trovare i parametri della rete (pesi) che minimizzano l'average loss (quantificato mediante la funzione di loss scelta) su un training set di dati. L'obiettivo finale è costruire un modello che garantisca un loss medio basso su tutti i possibili input. Dato l'elevato numero di parametri di una rete neurale (specialmente se deep) il rischio di overfitting è alto. Concentriamoci inizialmente sulla minimizzazione della funzione di loss sul training set.
4.1 Derivate parziali e gradiente
È possibile estendere l'idea della derivata alle funzioni multivariate. Sia una funzione ad variabili. La derivata parziale di rispetto alla componente -esima è:
Per calcolare la derivata parziale di rispetto alla componente -esima è sufficiente trattare tutte le variabili meno che la -esima come costanti e calcolare la derivata di . Le seguenti notazioni sono equivalenti:
Raggruppando le derivate parziali di una funzione multivariata rispetto ad ognuna delle sue componenti otteniamo il vettore gradiente della funzione. Supponiamo che l'input della funzione sia un vettore -dimensionale e che l'output sia invece uno scalare. Il gradiente della funzione rispetto ad è un vettore di derivate parziali:
Sia un vettore -dimensionale, le seguenti regole sono spesso utilizzate nella differenziazione di funzioni multivariate:
Similmente, per ogni matrice , abbiamo che .
4.2 Matrice jacobiana
Sia un vettore di valori reali. Sia ed . La matrice jacobiana di rispetto ad è la matrice formata dalle derivate parziali prime di ciascuna componente di rispetto a ciascuna componente di :
4.3 Metodo di discesa del gradiente
Il metodo di discesa del gradiente (gradient descent) è una tecnica atta ad individuare i punti di minimo (o di massimo) di una funzione di più variabili. Nel contesto delle reti neurali la funzione da minimizzare è la funzione loss calcolata sui parametri correnti del modello.
Partendo da un valore iniziale assunto dai parametri della funzione, il metodo iterativamente cerca la direzione di massima discesa del valore della funzione e aggiorna i valori dei parametri seguendo tale direzione. La direzione di massima discesa è quella opposta al gradiente (o alla matrice jacobiana nel caso in cui il codominio della funzione è multidimensionale).
4.3.1 Schema del metodo
Sia la funzione loss da minimizzare. Indichiamo con la matrice di parametri della rete neurale calcolato dall'algoritmo all'iterazione . La procedura generale dell'algoritmo di discesa del gradiente è la seguente:
- Per inizializzare la matrice dei pesi con valori casuali.
- Calcolare la funzione loss con i parametri ed il gradiente .
- Aggiornare la matrice dei pesi
- Passare alla iterazione successiva e ripartire dal secondo step.
Il metodo viene iterato sino a quando i valori del vettore non cambiano in maniera significativa. Analogo metodo per la matrice Jacobiana. Essendo basato su una scelta greedy, non garantisce l'individuazione di minimi assoluti, per cui può convergere ad un minimo locale. Il vettore ottenuto dopo la convergenza dell'algoritmo contiene i parametri della rete che minimizzano la funzione loss.
4.3.2 Learning rate
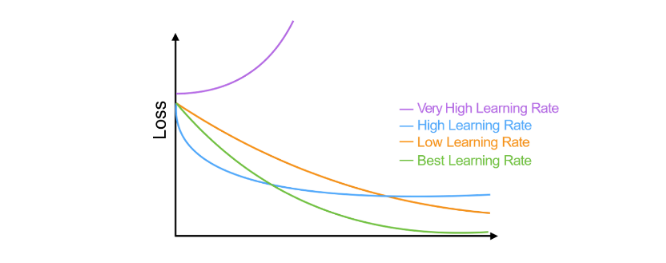
Il parametro (eta) è detto learning rate e determina la velocità con cui si desidera che il metodo converga al valore ottimale. Valori troppo bassi implicano che la convergenza richieda molte iterazioni. Dall'altra parte, valori molto alti possono causare grandi oscillazioni nei valori dei parametri della rete, impedendo di arrivare a convergenza. Un metodo per trovare il learning rate ottimale consiste nel partire da un valore alto di e ad ogni passo moltiplicare per un fattore (con ) fino ad ottenere un valore di che porti a convergenza.
4.3.3 Inizializzazione dei pesi della rete
Per applicare il metodo di discesa del gradiente occorre partire da un valore iniziale della funzione loss, poiché quest'ultima deve essere calcolata su una rete neurale già definita con dei pesi assegnati. Si pone quindi il problema di inizializzare i pesi della rete. Intuitivamente, se vogliamo che i nodi di un layer si comportino in maniera diversa (e riconoscano feature diverse sugli input ricevuti) occorre scegliere dei pesi diversi. Vi sono due approcci:
- Scegliere casualmente pesi in seguendo una distribuzione uniforme
- Scegliere casualmente secondo una distribuzione normale
4.3.4 Stochastic gradient descent
Il metodo stochastic gradient descent è una variante della discesa del gradiente in cui, ad ogni iterazione del metodo, si lavora su un piccolo campione di dati del training set selezionato in maniera casuale. Tale variante risulta più veloce del gradient descent originale quando il training set è troppo grande.
4.3.5 Calcolo del gradiente
Una volta calcolata la funzione loss su un vettore di output, occorre calcolare il gradiente della funzione loss rispetto ai pesi della rete in quel determinato momento. Un algoritmo efficiente per il calcolo del gradiente è l'algoritmo di backpropagation, che sfrutta il concetto di grafo computazionale.
4.4 Backpropagation
4.4.1 Forward propagation
Il termine forward propagation (o forward pass) si riferisce al calcolo e all'archiviazione ordinata di variabili intermedie della rete neurale, dall'input layer all'output layer.
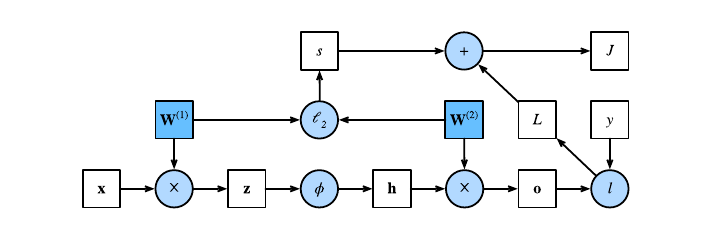
Per semplicità assumiamo che l'input d'esempio sia e che vi sia un solo layer nascosto nella rete, che non includa alcun termine di bias. Sia una variabile intermedia: Dove è la matrice dei pesi dell'unico hidden layer. Diamo in input tale variabile alla funzione di attivazione e otteniamo un vettore di attivazione di lunghezza : Anche la variabile è una variabile intermedia. Assumendo che l'output layer possegga una matrice di pesi , otteniamo il risultato dell'output layer e poniamolo in una variabile temporanea di lunghezza : Assumendo che la funzione loss sia e che la classe dell'esempio sia , possiamo calcolare la loss per la predizione di come segue: Dalla definizione della regolarizzazione , dato un parametro , il termine di regolarizzazione è Dove la norma di Frobenius (o norma matriciale) è semplicemente la norma applicata dopo aver concatenato la matrice in un singolo vettore. Otteniamo quindi l'ultimo termine , ovvero la loss regolarizzata: Ci riferiremo a con il nome di objective function o funzione loss regolarizzata
4.4 Grafo computazionale
Un grafo computazionale è un grafo aciclico diretto (DAG) che permette di visualizzare il flusso di dati di una rete neurale. Ogni nodo può avere due forme: un nodo quadrato indica un valore (tensore di dimensione arbitraria), mentre un nodo circolare indica una operazione. La direzione indica che il nodo mittente è operando del nodo destinatario, o che il nodo destinatario è output del nodo mittente. Visualizziamo il grafo computazionale della rete neurale descritta dalla forward propagation:
4.5 Chain rule
La regola della catena, in inglese chain rule, è una regola di derivazione che permette di calcolare la derivata di una funzione composta da due funzioni derivabili.
Supponiamo che le funzioni ed ) siano entrambe differenziabili, la regola della catena enuncia che: Nel caso più generale di funzioni multivariate, supponiamo che la funzione differenziabile abbia variabili, e che ogni funzione differenziabile abbia variabili. La regola della catena enuncia che per calcolare la derivata parziale di rispetto ad è sufficiente calcolare: per .
4.6 Algoritmo di backpropagation
L'algoritmo di backpropagation è utilizzato nel calcolo del gradiente della funzione loss rispetto ai parametri (pesi) della rete neurale. In breve, il metodo percorre la rete neurale in verso opposto, dall'output layer all'input layer, e calcola il gradiente sfruttando la regola della catena.
L'algoritmo conserva le derivate parziali intermedie ad ogni iterazione e le ri-utilizza per calcolare altre derivate parziali andando indietro nel grafo computazionale. Ipotizziamo due funzioni e , in cui sono tensori di dimensione arbitraria. Utilizzando la regola della catena, possiamo calcolare la derivata di rispetto ad come segue:
Dove l'operatore prod generalizza la chain rule in base alla dimensione dei tensori. Riprendiamo l'esempio visto nella forward propagation di rete neurale ad un solo hidden layer, in cui è la matrice dei pesi dell'hidden layer, mentre è la matrice dei pesi dell'output layer.
Sia la funzione costo regolarizzata, l'obiettivo della backpropagation è quello di calcolare i gradienti e . Per ottenere ciò, calcoliamo a turno i gradienti rispetto ad ogni variabile intermedia utilizzando la chain rule.
Partendo in ordine inverso, il primo step consiste nel calcolare il gradiente della funzione costo regolarizzata rispetto al termine di loss e rispetto al termine di regolarizzazione . Calcoliamo il gradiente della funzione loss regolarizzata rispetto al risultato dell'output layer , seconda la regola della catena: Calcoliamo il gradiente del termine di regolarizzazione rispetto ad entrambe le matrici di parametri e , ricordando di aver utilizzato la regolarizzazione : È possibile adesso calcolare il gradiente (in questo caso una matrice Jacobiana) della funzione loss regolarizzata rispetto ai parametri dell'output layer utilizzando la regola della catena: Per ottenere il gradiente di rispetto ai parametri dell'hidden layer è necessario continuare la backpropagation dall'output layer all'hidden layer. Il gradiente della funzione loss regolarizzata rispetto all'output dell'hidden layer è dato da: Dato che la funzione di attivazione viene applicata ad ogni elemento di , calcolare il gradiente di rispetto a richiede l'utilizzo dell'operatore di moltiplicazione element wise denotata dal simbolo : In conclusione, è possibile ottenere il gradiente (anche in questo caso una matrice Jacobiana) della funzione rispetto ai parametri dell'hidden layer utilizzando la regola della catena:
4.7 Sommario
Ricapitolando, data una rete neurale ed un training set :
- Si assegna ad una matrice di pesi iniziali scelti casualmente.
- Si addestra la rete neurale con la matrice attuale di pesi su .
- A partire dagli output prodotti dalla rete neurale su e dagli output noti per , viene calcolata la loss media su (su tutti gli esempi del training set).
- Usando l'algoritmo di backpropagation si calcola il gradiente di L rispetto a .
- Si effettua una iterazione del metodo di discesa del gradiente per aggiornare la matrice dei pesi.
- Si iterano i passi da 2 a 5 sino a quando la loss media non decresce più significativamente oppure dopo un numero fissato di iterazioni (dette anche epoche).
4.8 Monitoraggio di qualità
Con i pesi ottenuti ad ogni iterazione del learning sul training set, si testa la rete neurale sul test set e si calcola la loss. L'obiettivo è quello di far diminuire ad ogni epoca il valore della funzione loss sia sul training set che sul test set.
4.8.1 Overfitting
Lo scopo finale del processo di training è minimizzare la loss media su nuovi input. Un problema abbastanza comune è quello di costruire un modello che funziona molto bene sul training set, ma non generalizzabile e funzionante su nuovi input, ovvero il famoso problema dell'overfitting. Le deep neural network sono particolarmente suscettibili all'overfitting, tuttavia esistono dei metodi di regolarizzazione che aiutano a ridurlo.
4.8.2 Aggiunta di penalità
Il metodo di discesa del gradiente potrebbe convergere ad un minimo locale che non corrisponde al minimo assoluto della funzione di loss. Nella pratica si osserva che soluzioni in cui i pesi hanno valori assoluti piccoli producono modelli migliori e più generalizzabili rispetto a soluzioni con pesi grandi. È possibile forzare il metodo del gradiente a favorire soluzioni con peso piccolo aggiungendo un termine di penalità alla loss function usata dal modello: Dove è un iperparametro di tuning che serve a configurare l'importanza della regolarizzazione. Più alti sono i pesi e maggiore è la norma del vettore dei pesi, quindi maggiore è la penalità introdotta. Solitamente si considera la norma 2, ovvero:
4.9 Dropout
Nei capitoli precedenti si è vista la tecnica di bootstrapping utilizzata nella classificazione. Analogamente, viene utilizzata una tecnica che prende il nome di dropout nelle reti neurali. Lo scopo è quello di creare un consenso sui valori ottimali dei pesi, considerando il risultato ottenuto da diverse sottoreti neurali. Ad ogni epoca si seleziona in maniera random una frazione dei nodi della rete, chiamata dropout rate, e si rimuovono. Sulla rete neurale ridotta si effettua una iterazione del metodo di discesa del gradiente. Dal momento in cui la rete neurale completa contiene più nodi rispetto a quella utilizzata durante il training, alla fine del processo di allenamento i pesi ottenuti vengono ri-scalati, ovvero moltiplicati per il dropout rate.
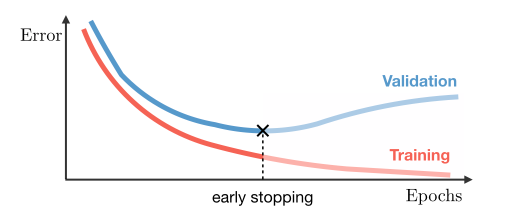
4.10 Early stopping
Nella pratica si osservano comportamenti diversi della funzione di loss sul training set e sul test set. Nel training set la funzione loss decresce durante l'addestramento. Nel test set potrebbe succedere che la funzione loss decresca sino a raggiungere un minimo e, dopo un certo numero di iterazioni, cresca (overfitting). Per evitare questo problema, si può fermare prematuramente il training non appena la loss smette di decrescere nel test set.
Il rischio che si corre con l'early stopping è quello di produrre overfitting sul test set. Per evitare ciò si può costruire un validation set indipendente dai primi due. Si effettua l'early stopping osservando l'andamento dalla funzione loss sul training set e sul validation set. Si ferma il processo quando, mentre la loss sul training set decresce, sul validation set comincia a crescere.
4.11 Aumento del training set
L'accuratezza delle reti neurali è proporzionale alla quantità di dati nel training set. Training set più grandi producono meno overfitting. È possibile arricchire un training set aggiungendo dati artificiali ottenuti applicando trasformazioni ai dati reali o inserendo del rumore. Ad esempio, se la rete neurale è addestrata per classificare immagini (es. convolutional network), si potrebbe incrementare il training set ruotando le immagini o distorcendole con del rumore.
5. Tipologie di reti neurali
5.1 Feed-Forward Networks (FFNs)
Una rete neurale feed-forward ("rete neurale con flusso in avanti") o rete feed-forward è una rete neurale artificiale dove le connessioni tra le unità non formano cicli, differenziandosi dalle reti neurali ricorrenti. Questo tipo di rete neurale fu la prima e più semplice tra quelle messe a punto. In questa rete neurale le informazioni si muovono solo in una direzione, avanti, rispetto a nodi d'ingresso, attraverso nodi nascosti (se esistenti) fino ai nodi d'uscita. Nella rete non ci sono cicli. Le reti feed-forward non hanno memoria di input avvenuti a tempi precedenti, per cui l'output è determinato solamente dall'attuale input.
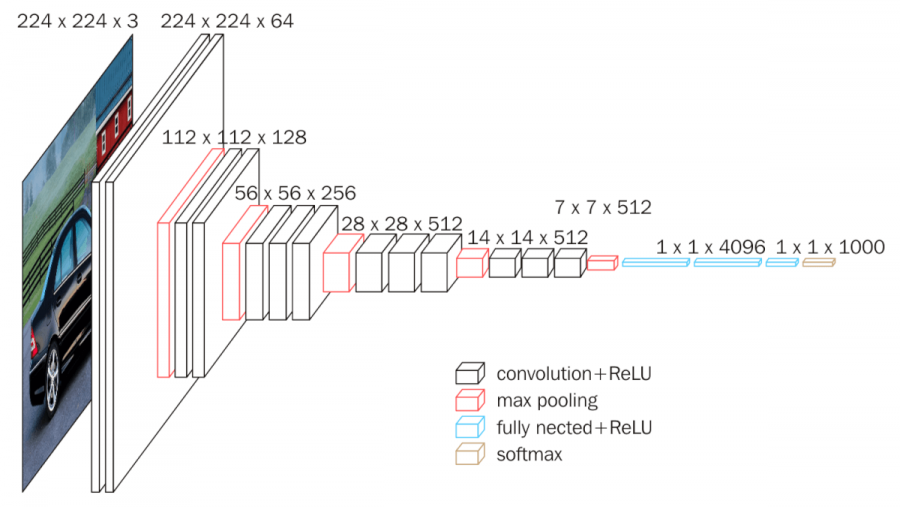
5.2 Convolutional Neural Networks (CNN)
Una rete neurale convoluzionale (CNN o ConvNet dall'inglese convolutional neural network) è un tipo di rete neurale artificiale feed-forward in cui il pattern di connettività tra i neuroni è ispirato dall'organizzazione della corteccia visiva animale, i cui neuroni individuali della retina (fotorecettori) sono disposti in layer. Hanno diverse applicazioni nel riconoscimento di immagini e video, nei sistemi di raccomandazione, nell'elaborazione del linguaggio naturale e, recentemente, in bioinformatica.
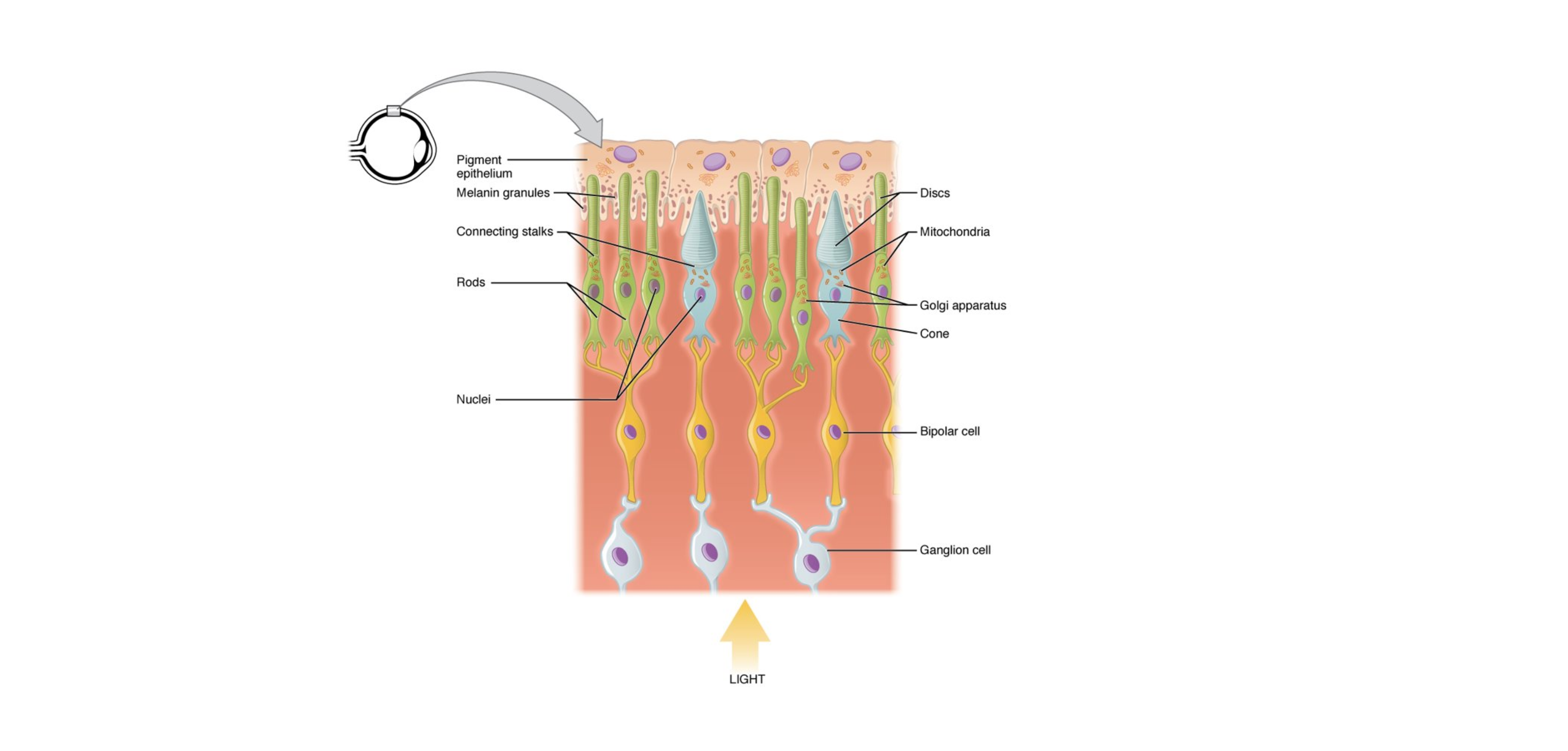
Una rete neurale convoluzionale contiene uno o più layer convoluzionali. I nodi all'interno di un layer convoluzionale condividono gli stessi pesi per gli input. Generalmente si alternano i layer convoluzionali a dei layer pooled (o a volte densi) con un numero di nodi progressivamente minore.
Il primo layer coglie le informazioni che rappresentano i pixel essenziali delle immagini, ovvero i contorni. Lo schema di riconoscimento dei contorni è sempre lo stesso e non dipende dal punto in cui viene osservato un contorno (in analogia col fatto che in una CNN i nodi dello stesso layer condividono i pesi degli input). I successivi layer della retina combinano i risultati dei precedenti layer per riconoscere strutture via via più complesse (es. regioni dello stesso colore e infine volti e oggetti).
5.2.1 Convolutional layer
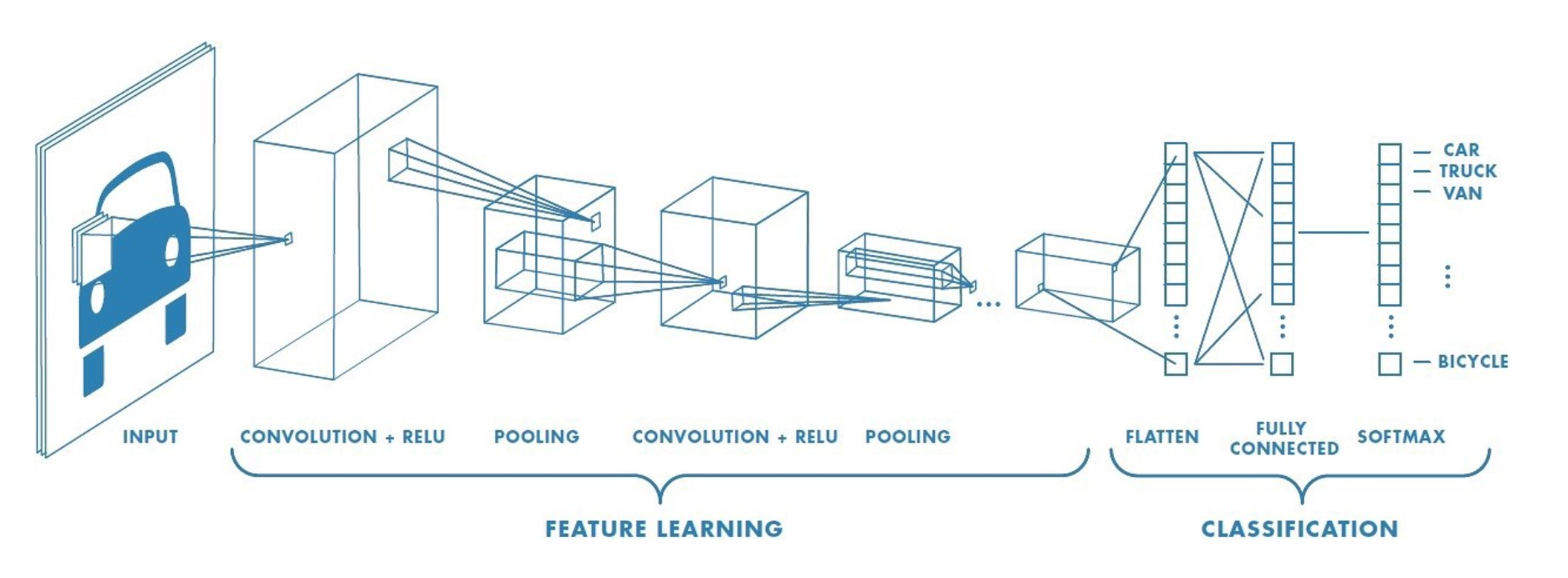
Un layer convoluzionale è formato da una griglia di nodi. Ogni nodo può essere immaginato come un filtro di dimensione applicato in un punto della griglia di nodi del layer precedente, ed è detta dimensione del filtro. Nell'ambito dell'image processing, questo equivale ad applicare un filtro in un pixel di una immagine. Se il nodo della convolutional layer applica il filtro sul nodo della griglia di nodi del layer precedente, si considera il quadrato di dimensione il cui vertice in alto a sinistra è e si calcola il valore di output come segue: Se anziché considerare il vertice in alto a sinistra si considerasse il centro, la formula assumerebbe un'altra forma. Per calcolare l'output di tutti i nodi del layer convoluzionale bisogna scorrere il filtro (uguale per tutti i nodi) in lungo ed in largo sulla griglia del layer precedente ed applicarlo. Il risultato è una convoluzione del filtro sull'immagine prodotta dal layer precedente, da cui il nome. Lo stride di un filtro indica di quante posizioni si deve scorrere una volta applicato il filtro. Se allora l'immagine in output avrà la stessa dimensione dell'immagine in input, se allora sarà più piccola.
5.2.2 Zero padding
A seconda delle dimensioni della matrice di input ricevuta, la matrice di output prodotta potrebbe avere dimensioni inferiori anche con stride pari ad 1.Nell'esempio sottostante, partendo dai pixel nell'angolo in basso a destra dell'input potrebbe essere impossibile costruire un quadrato di dimensione . Per ottenere un output delle stesse dimensioni dell'input, una tecnica semplice consiste nell'aggiungere alla matrice di input righe e colonne di . Questa tecnica prende il nome di zero padding.
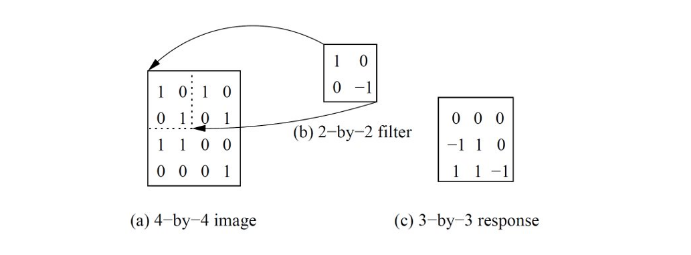
5.2.3 Pooling layer
Un pooling layer prende in input l'output di un layer convoluzionale e produce un output più piccolo. La riduzione è effettuata mediante una funzione di pooling (es. funzione max) che aggrega i valori di una piccola regione intorno all'input. La funzione di pooling agisce su un quadrato di lato di valori di input. Per ottenere l'output completo, il quadrato viene fatto scorrere in lunghezza e larghezza di un valore di stride . Più alti sono i valori ed e più piccolo sarà l'output. Valori troppo grandi di possono portare ad una perdita di informazione.
5.2.4 CNN su immagini a colori
In un'immagine a colori l'input è costituito da 3 canali (RGB). Ogni canale è formato da una matrice di valori (intensità dei pixel). In questo caso, il filtro applicato sia nel convolutional layer che nel pooling layer ha dimensione . Tutti i nodi di uno stesso layer utilizzeranno una matrice di di pesi.
5.3 Recurrent Neural Networks (RNNs)
Una Recurrent Neural Network (RNN) è una rete neurale che può contenere dei cicli. L'output di un layer può diventare l'input per un layer posto precedentemente o per se stesso. Questa disposizione è equivalente ad una rete neurale in cui uno o più layer ricorrono più volte.
I layer ricorrenti possono essere utilizzati come memoria dello stato, per ricordare i valori osservati in passato. Fornendo una sequenza temporale di valori è possibile modellare un comportamento dinamico temporale che dipende dalle informazioni agli istanti di tempo precedenti. Ciò rende le RNN adatte alla predizione di valori successivi a partire da una sequenza di eventi osservati. In breve, mentre le CNN possono processare in maniera efficiente dati tabulari, le RNN sono progettate per gestire al meglio le informazioni sequenziali. Le applicazioni tipiche risiedono nel language processing e nel riconoscimento vocale.
5.3.1 Struttura tipica di una RNN
Definiamo l'input e l'output di un layer ricorrente come due sequenze e . I pesi condivisi dai nodi del layer ricorrente sono rappresentati da 3 matrici come nella figura sottostante. Sia uno stato nascosto che funziona da memoria delle informazioni rappresentate dalla sottosequenza osservata sino al tempo .
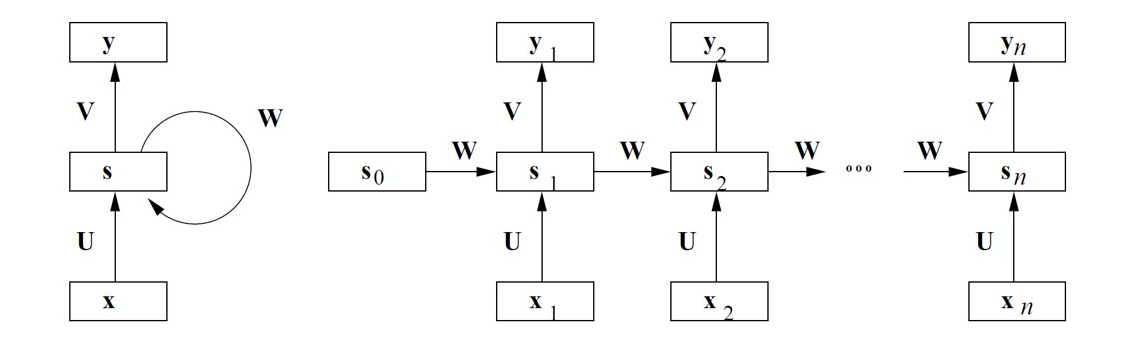
Lo stato nascosto è definito come vettore di zeri. Lo stato nascosto al tempo si ottiene applicando una funzione di attivazione non lineare (es. sigmoid, tanh) considerando l'input al tempo e lo stato nascosto al tempo : Dove è un vettore di bias. L'output al tempo è ottenuto applicando una seconda funzione di attivazione (es. softmax) considerando lo stato nascosto al tempo : Dove è un vettore di bias.
5.3.2 Varianti
In alcune applicazioni (es. la traduzione di una frase) è necessario un unico output da produrre alla fine del processo. In questo caso gli output prodotti ad ogni step dalla RNN vengono passati ad uno o più layer totalmente connessi che genereranno l'output finale.
5.3.3 Sequenze di lunghezza variabile
Per gestire sequenze di lunghezza variabile si possono utilizzare due tecniche:
- Zero padding: si fissa come lunghezza massima della sequenza che la RNN può gestire e, se una sequenza è più corta, si aggiungono zeri fino ad ottenere una sequenza lunga .
- Bucketing: raggruppa le sequenze sulla base della loro lunghezza e costruisce una RNN diversa per ogni valore di lunghezza.
È possibile combinare le due tecniche: si costruiscono diversi bucket, ciascuno dei quali è in grado di gestire sequenze di lunghezza simile in un piccolo intervallo di valori. Si assegna la sequenza in input al bucket in grado di gestire sequenze della stessa lunghezza o di lunghezza leggermente più alta. In quest'ultimo caso si effettua il padding.
5.3.4 Limiti delle RNN
Le RNN sono efficaci solo nell'apprendimento di relazioni o connessioni tra elementi vicini nella sequenza, mentre non sono in grado di apprendere relazioni tra elementi distanti. Ciò può essere problematico nell'apprendimento di un testo. Un verbo o un pronome possono essere separati da molte parole dal soggetto della frase. A livello di calcolo del gradiente, ciò si riflette in una instabilità dei valori, con una saturazione o una esplosione della derivata prima della funzione di attivazione.
5.4 Long Short-Term Memory (LSTM)
La tecnica Long Short-Term Memory (LSTM) è un raffinamento delle RNN che affronta il problema delle connessioni a lunga distanza. Le proprietà di una rete LSTM possono essere riassunte da tre verbi:
- Forget, la capacità di eliminare dalla memoria informazioni che non servono più. Ad esempio, nell'analisi di un testo potremmo scartare informazioni su una frase quando termina.
- Save, la capacità di salvare determinate informazioni in memoria. Ad esempio, nell'analisi di un testo potremmo salvare solo le parole chiave di una frase quando termina.
- Focus, la capacità di focalizzarsi solo su aspetti della memoria immediatamente rilevanti. Ad esempio, nell'analisi di un testo possiamo concentrarci solo su parole che riguardano il contesto della frase attualmente analizzata.
Per realizzare tali proprietà si necessita di una memoria a lungo termine (con informazioni sulla parte di sequenza già analizzata) e di una memoria corrente (con informazioni di immediata rilevanza).

5.4.1 Struttura di una LSTM
Gli stati rapresentano le due tipologie di memoria:
- Stato nascosto: vettore al tempo che indica la memoria corrente;
- Cell state: vettore al tempo che indica la memoria a lungo termine;
IL vettore contiene l'update temporaneo dello stato nascosto. I gate sono vettori usati per far passare selettivamente alcune informazioni di uno stato scartando il resto. Vi sono 3 gate:
- L'input gate determina quali parti del vettore salvare nella memoria long-term;
- Il forget gate che determina quali aspetti della memoria long-term mantenere;
- L'output gate che indica quali parti della memoria long-term spostare nella memoria corrente.
5.4.2 Aggiornamento del cell state
Il primo passo per aggiornare il cell state è calcolare l'update temporaneo dello stato nascosto : Dopodiché si calcolano l'input gate ed il forget gate: Si aggiorna la memoria a lungo termine: Dove sono matrici di pesi e sono vettori di bias. Il simbolo indica il prodotto di Hadamard, ovvero il prodotto puntuale tra vettori o matrici.
5.4.3 Calcolo dello stato nascosto
Per calcolare lo stato nascosco (ovvero la memoria corrente) è necessario calcolare l'output gate E aggiornare la memoria come segue Dove è una matrice di pesi e è un vettore di bias.
5.4.4 Calcolo dell'output
L'output è calcolato allo stesso modo di qualsiasi RNN: Dove è una funzione di attivazione, è una matrice di pesi e è un vettore di bias.