Catene di Markov e Hidden Markov Models
1. Catene di Markov
Una catena di Markov è una tripla dove:
- è un insieme finito di stati (o eventi).
- denota lo stato osservato all'i-esimo istante di tempo.
- rappresenta l'insieme delle probabilità iniziali per ogni stato.
- è l'insieme delle probabilità di transizione denotate da per ogni .
Nello specifico, denota la probabilità che all'istante di tempo si verifichi lo stato dato per assunto che all'istante di tempo si sia presentato lo stato . Di fatto si parla di una transizione di stati e si rappresenta attraverso il concetto di probabilità condizionata:
Sia n la cardinalità dell'insieme degli stati , l'insieme è esprimibile attraverso una matrice, chiamata matrice di transizione di dimensione , dove l'elemento rappresenta la probabilità di passare dallo stato allo stato .
1.1 Proprietà memoryless
Generalemente si parla di catene di Markov del primo ordine quando lo stato successivo dipende esclusivamente dallo stato corrente. Tale proprietà prende il nome di proprietà memoryless. Formalmente, se è la sequenza di stati osservati, si ha: Quindi la probabilità che all'istante di tempo si abbia dipende solo dal fatto che allo stato . Tale probabilità è esprimibile attraverso la transizione tra lo stato e lo stato , ovvero .
1.2 Probabilità di una sequenza di eventi
Consideriamo la seguente catena di Markov (immagine sottostante) dove i nodi rappresentano i possibili stati e gli archi le transizioni possibili con le rispettive probabilità. Supponiamo di osservare una sequenza di stati del genere: con probabilità iniziali . Come calcoliamo la probabilità che si verifichi tale sequenza?
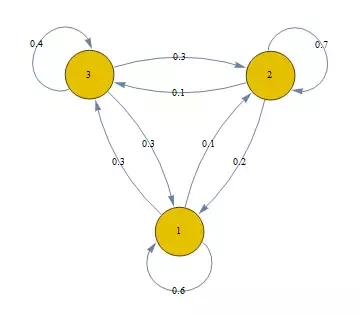
Vogliamo quindi calcolare la probabilità , che risulta essere una probabilità congiunta. In generale, per le proprietà sul prodotto logico tra eventi si ha: Ma ricordiamo che vale la proprietà memoryless, per cui: Applichiamo tali concetti alla sequenza d'esempio e otteniamo:
1.3 Matrice stocastica
Nella matrice di transizione di una catena di Markov la somma degli elementi di ciascuna riga è uguale ad 1, ovvero da ciascuno stato è sempre possibile raggiungere uno qualsiasi degli stati della catena (anche stesso), e la somma delle probabilità di transizione è 1. In virtù di tale proprietà la matrice di transizione è detta stocastica. Vediamo la matrice di transizione della catena in esempio:
| Stato 1 | Stato 2 | Stato 3 | |
|---|---|---|---|
| Stato 1 | 0.6 | 0.1 | 0.3 |
| Stato 2 | 0.2 | 0.7 | 0.1 |
| Stato 3 | 0.3 | 0.3 | 0.4 |
1.4 Classificazione delle catene di Markov
Una catena di Markov si dice irriducibile se da ogni stato è possibile raggiungere un qualsiasi altro stato della catena mediante una o più transizioni.
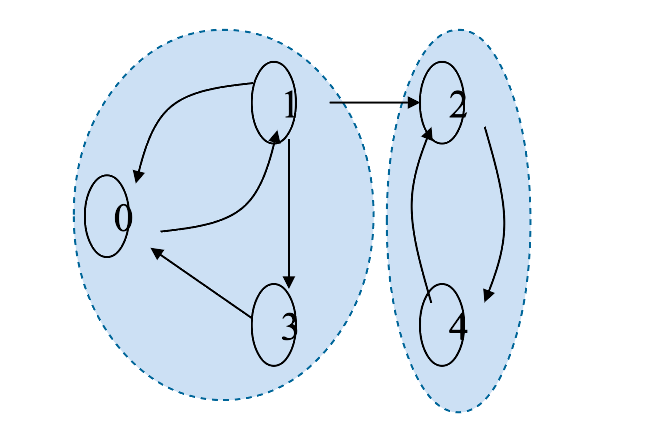
Definiamo periodo di uno stato come il minimo numero di passi necessari per tornare ad con probabilità non nulla. Se il periodo è maggiore di 1, lo stato è detto periodico. Una catena di Markov aperiodica è una catena in cui nessuno stato è periodico.
1.5 Probabilità di eventi successivi
Prendiamo in considerazione la seguente catena di Markov:
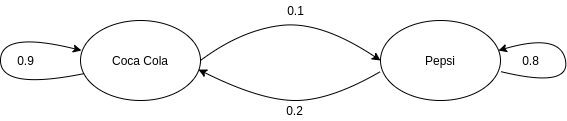
Essa indica che una persona che compra Coca-Cola nel 90% dei casi la prossima volta comprerà Coca-Cola. Se una persona compra Pepsi allora nell'80% dei casi la prossima volta comprerà Pepsi. Visualizziamo la matrice di transizione:
| Coca Cola (C) | Pepsi (P) | |
|---|---|---|
| Coca Cola (C) | 0.9 | 0.1 |
| Pepsi (P) | 0.2 | 0.8 |
Domanda: per una persona che attualmente compra Pepsi, qual è la probabilità che tra due volte acquisterà Coca Cola?
La probabilità richiesta è esprimibile come: Tuttavia lo stato a tempo dipende solo dallo stato , che può essere sia Coca-cola che Pepsi. Essendo due casi favorevoli, vanno considerati entrambi e vanno sommate le probabilità. Per cui adesso necessitiamo di: Calcoliamo entrambe le probabilità attraverso la matrice di transizione: Calcoliamo la somma delle due probabilità: Osservazione Se effettuiamo il prodotto riga colonna tra la matrice A e se stessa otterremo un'ulteriore matrice della stessa dimensione, dove ogni elemento indica la probabilità di due transizioni, la cui transizione di mezzo può essere uno qualsiasi tra gli stati. Di fatto l'elemento di indici indica la probabilità che, partendo dallo stato si possa arrivare allo stato in due transizioni con probabilità del 34%.
A questo punto è possibile generalizzare il concetto: per una persona che compra Coca Cola, qual è la probabilità che tra n volte comprerà Pepsi? Allora basterà effettuare il prodotto riga colonna della matrice A con se stessa per n volte.
Sia la distribuzione di probabilità iniziale. Ogni qual volta effettuiamo un prodotto riga-colonna otteniamo una distribuzione differente. Si può dimostrare che ad un certo punto si arriverà ad una distribuzione stazionaria in cui le probabilità non varieranno.
1.5.1 Distribuzione stazionaria
Sia una catena di Markov del primo ordine, irriducibile e aperiodica con k stati. Si dimostra che: Tale proprietà vale per tutti gli , dunque si ottiene un vettore di valori . Se contiene valori non nulli, allora è detta distribuzione stazionaria. Se tutti i valori di sono non nulli allora è l'unica distribuzione stazionaria.
2. Hidden Markov Models (HMM)
Un modello di Markov nascosto (in inglese Hidden Markov Model o HMM) è un modello più ricco rispetto alla catena di Markov. A differenza di una catena di Markov, in un HMM gli stati sono nascosti. Ogni stato emette un simbolo con una certa probabilità. L'osservatore vede soltanto una sequenza di simboli emessi in base alla quale può dedurre la probabilità di osservare la corrispondente sequenza di stati associati.
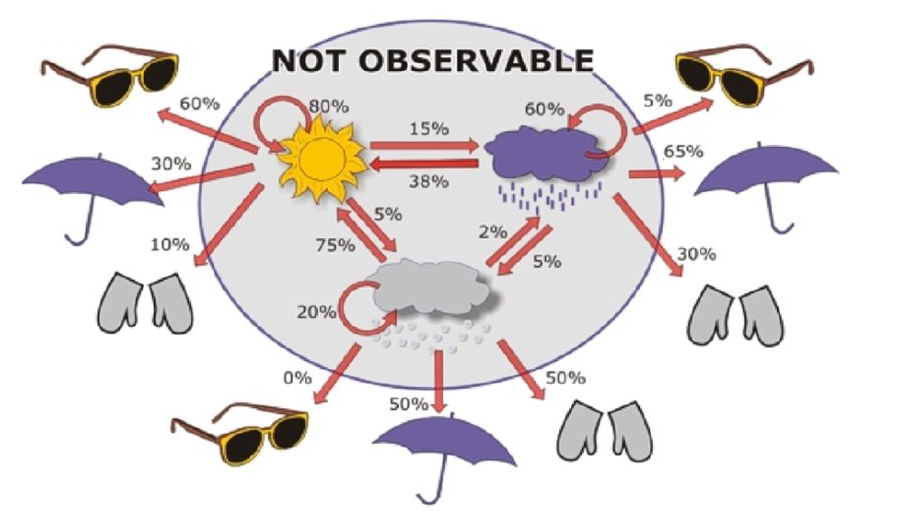
2.1 Definizione
Una Hidden Markov Model è una quintupla dove:
- è un insieme finito di stati (o eventi).
- denota lo stato osservato all'i-esimo istante di tempo.
- rappresenta l'insieme delle probabilità iniziali per ogni stato.
- è la matrice delle probabilità di transizione denotate da per ogni .
- è un alfabeto composto da m simboli.
- denota il simbolo emesso all'i-esimo istante di tempo.
- è la matrice di emissione di dimensione contenente per ogni stato e ogni simbolo la probabilità che emetta . Si scrive:
2.2 Problemi principali su HMM
I problemi principali legati alle Hidden Markov Models sono i seguenti:
- Evaluation: Sia un HMM ed X una sequenza di simboli, calcolare la probabilità della sequenza.
- Decoding: Sia un HMM ed X una sequenza di simboli, trovare la sequenza di stati che massimizza .
- Learning: Sia M un HMM con probabilità di transizione e di emissione note, ed una sequenza , trovare i parametri del modello che massimizzano .
Esempio: Ipotizziamo che in un casinò vi sia un croupier disonesto con due dadi, uno regolare ed uno truccato. Il dado regolare ha equiprobabilità nell'emettere un qualsiasi numero tra 1 e 6; il dado truccato ha una probabilità maggiore di emettere 6 rispetto agli altri numeri. Data una sequenza di lanci risolvere i seguenti problemi:
- Evaluation: Nota la HMM, qual è la probabilità di ottenere questa sequenza di risultati?
- Decoding: Quando il croupier ha utilizzato il dato regolare e quando quello truccato?
- Learning: Quali sono le matrici di transizione ed emissione che massimizzano la probabilità di ottenere questi risultati?
2.3 Evaluation
Dato un HMM ed una sequenza di simboli qual è la probabilità di ottenere tale sequenza?
Supponiamo di fissare la sequenza di stati (incognita). La probabilità di osservare gli n simboli della sequenza emessi dagli n stati di è data da: Ci avvaliamo delle proprietà sul prodotto logico, per cui: Supponendo che la catena di Markov sia del primo ordine, allora esprimiamo il primo fattore del prodotto come: Osserviamo il secondo fattore: ci accorgiamo che la probabilità di emettere il simbolo dipende solo dallo stato , per cui è possibile scomporre tutto in un semplice prodotto di probabilità condizionate: Ma corrisponde alla elemento della matrice di transizione e corrisponde all'elemento della matrice di emissione, per cui riscriviamo l'espressione finale come segue:
2.3.1 Probabilità forward
Nel ragionamento precedente abbiamo assunto una sequenza di stati . Tuttavia per ottenere la probabilità della sequenza data è necessario sommare le probabilità date da tutte le sequenze possibili di stati che possono emettere la data sequenza: Per evitare la somma, che coinvolge un numero esponenziale di sequenze di stati , definiamo: La funzione è chiamata probabilità forward, ovvero la probabilità di osservare una sequenza di simboli emessi da una sequenza di stati tale che il t-esimo stato (stato al tempo t) sia .
È possibile calcolare la probabilità forward in maniera induttiva, dove il caso base corrisponde a: Mentre il passo induttivo è il seguente: Il passo induttivo deriva dal fatto che allo stato al tempo ci si possa arrivare da uno qualunque degli stati precedenti visitato al tempo , dopo avere emesso i simboli . Per arrivare allo stato da effettuo una transizione , ed infine si emette il simbolo corrispondente .
A partire dalla probabilità forward, possiamo ottenere la probabilità finale come: Ricordando che k è il numero di stati ed n è la lunghezza della sequenza .
Applicare l'algoritmo forward equivale a percorre tutti i possibili cammini di un particolare tipo di grafo, chiamato lattice, dove i k stati sono disposti in colonna e ripetuti n volte:
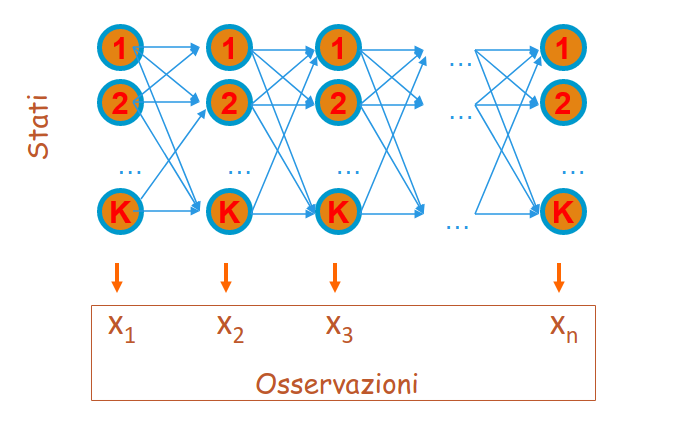
2.3.2 Algoritmo forward
Dalle precedenti relazioni segue il seguente algoritmo di programmazione dinamica con complessità , dove k è il numero di stati ed n è la lunghezza della sequenza .
X # array contenente la sequenza di simboli emessi
k # numero di stati
f # matrice delle probabilità forward,
# dove nelle righe risiedono i tempi e nelle colonne gli stati
E # matrice delle emissioni
A # matrice delle transizioni
# passo base
for i = 1 to k:
f[1,i] = P(pi_1 = i) * E[pi_1, i]
# passo induttivo
for t = 1 in len(X):
# per ogni stato j
for j = 1 to k:
sum = 0
# calcolo la probabilità di passare
# da uno qualsiasi tra gli stati
# precedenti i a j
for i = 1 in k:
sum = sum + f[t,i] * A[i,j]
# dopodiché moltiplico per la probabilità
# di emettere il simbolo x_{t+1}
simbol_to_emit = X[t+1]
f[t+1, j] = sum * E[j, simbol_to_emit]
# calcolo la probabilità finale sommando
# l'ultima riga della matrice, che conterrà
# le probabilità forward al tempo n per tutti
# gli stati.
p = 0
n = len(X) - 1
for i = 1 in k:
p = p + f[n, i]
return p
2.4 Decoding
Il secondo problema da affrontare è il decoding. Data una HMM ed una sequenza di simboli trovare la sequenza di stati che massimizza la probabilità congiunta di osservare gli simboli emessi dagli n stati di : Dove dai calcoli precedenti sappiamo che:
2.4.1 Algoritmo di Viterbi
L'algoritmo di Viterbi ha una struttura simile a quella dell'algoritmo forward. Tuttavia, anziché sommare i contributi provenienti da ogni singolo stato visitato al passo precedente, seleziona di volta in volta il contributo migliore, ovvero quello con il valore massimo. Ciò equivale nel lattice a tracciare un cammino di stati di lunghezza n che massimizzi la probabilità di ottenere la sequenza :
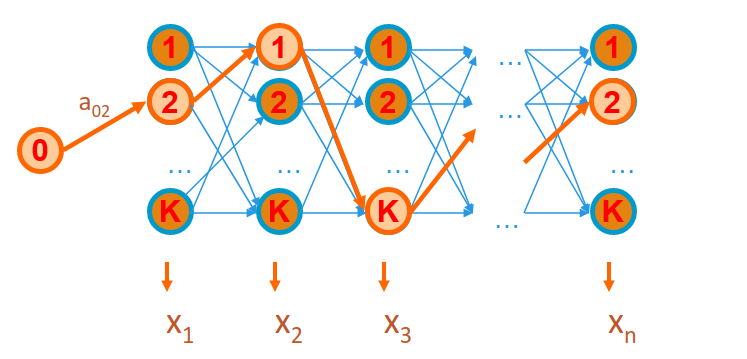
Definiamo una funzione : Come nel caso della probabilità forward, anche la funzione è definita per induzione, per cui definiamo prima il caso base: Mentre il passo induttivo è il seguente: Il passo induttivo deriva dal fatto che allo stato al tempo ci si possa arrivare da uno qualunque degli stati precedenti visitato al tempo , ma si seleziona solo lo stato con la probabilità maggiore dopo avere emesso i simboli . Per arrivare allo stato da effettuo una transizione , ed infine si emette il simbolo corrispondente .
A partire dalla funzione possiamo calcolare la probabilità finale come segue:
2.4.2 Pseudocodice dell'algoritmo
X # array contenente la sequenza di simboli emessi
k # numero di stati
V # matrice Viterbi, dove nelle righe risiedono i tempi e nelle colonne gli stati
E # matrice delle emissioni
A # matrice delle transizioni
phi # matrice per tener traccia del cammino
# dove nelle righe risiedono i tempi e nelle colonne gli stati
# passo base
for i = 1 in k:
V[1,i] = P(pi_1 = i) * E[pi_1, i]
phi[0, i] = 0
# passo induttivo
for t = 1 in len(X):
# per ogni stato j
for j = 1 in k:
_max = 0
phi[t, j] = 0
# cerco tra tutti i percorsi calcolati
# precedentemente quello con la probabilità
# maggiore di passare allo stato j-esimo
for i = 1 in k:
if (V[t, i] * A[i,j] > _max):
_max = V[t, i] * A[i,j]
phi[t,j] = i
# dopodiché moltiplico per la probabilità
# di emettere il simbolo x_{t+1}
simbol_to_emit = X[t+1]
V[t+1, j] = _max * E[j, simbol_to_emit]
# cerco quale tra i cammini di lunghezza n calcolati
# abbia probabilità maggiore di emettere gli n simboli
pmax = 0
n = len(X) - 1
for i = 1 in k:
if (V[n,i] > pmax):
pmax = V[n,i]
phi[n,i] = i
# ricostruisco il cammino attraverso i valori di phi
decoded_sequence = retrieve_path(phi)
2.4.3 Recuperare la sequenza di stati
Mediante la struttura dati si tiene traccia, ad ogni istante di tempo , degli stati migliori da cui si può provenire raggiungendo ogni stato del modello. In particolare, indica lo stato migliore da cui si può partire al tempo per raggiungere lo stato al tempo . Partendo dallo stato che massimizza , andando a ritroso, è possibile recuperare la sequenza completa degli stati che massimizza la probabilità finale di osservazione della sequenza di simboli.
2.5 Posterior Decoding
Il posterior decoding è un particolare problema di decoding. Avendo osservato una intera sequenza di simboli , si vuole calcolare (a posteriori) lo stato più probabile all'istante , ovvero lo stato tale che
Ma osserviamo che:
Il problema di massimizzazione è analogo se anziché il rapporto consideriamo solo la probabilità congiunta al numeratore, che tra l'altro possiamo esplicitare:
Dalle proprietà sul prodotto logico tra probabilità abbiamo:
Dove l'ultima semplificazione è possibile grazie alla proprietà memoryless delle catene di Markov del primo ordine. Il primo fattore del prodotto finale altro non è che la forward probability per , mentre il secondo fattore prende il nome di backward probability.
2.5.1 Probabilità backward
La probabilità di backward è la probabilità che si abbia una sequenza di simboli emessa da una sequenza di stati, dato per assodato che . Il ragionamento è analogo a quello dedotto dalla probabilità forward, per cui è possibile procedere per induzione:
Il passo base si ha quando , ovvero si effettua la supposizione . Ma osserviamo che non vi è nessuna sequenza da calcolare dato che n è la lunghezza massima della sequenza in input, per cui la probabilità sarà massima, .
Passo induttivo: Possiamo scomporre l'espressione: Essendo che ad ogni iterazione della sommatoria lo stato è fissato a , possiamo rimuovere dalla probabilità l'emissione dell'elemento (che sarà banalmente emesso dallo stato ) e la transizione dallo stato allo stato e moltiplicarli singolarmente: Ci accorgiamo che la probabilità corrisponde alla probabilità backward calcolata per , per cui sostituendo:
2.5.2 Algoritmo backward
Analogo all'algoritmo forward, l'algoritmo backward ha complessità , dove k è il numero di stati ed n è la lunghezza della sequenza .
# Sia X un array di lunghezza n contenente la sequenza di simboli emessa
# Sia B (Backward) una matrice le quali righe indicano i tempi, mentre le colonne gli stati
# Sia Q l'insieme di stati di cardinalità k
# Sia E la matrice d'emissione e A la matrice delle transizioni
def backward_probability(X, Q, Sigma):
n = len(X) - 1 # partiamo da 0
k = len(Q) - 1 # partiamo da 0
# passo base
for i in range(0, k):
B[n, i] = 1
# passo induttivo
# per ogni simbolo in sequenza, partendo dal penultimo
# poiché l'ultimo è coperto dal passo base
for t in range(0, n-1, -1): # da n-1 a 0
# eseguiamo il calcolo per ogni stato
for i in range(0, k):
probability = 0
# allo stato i ci si può arrivare attraverso
# uno stato qualsiasi tra i k stati disponibili
for j in range(0, k):
# prendo la probabilità del tempo t+1
# poiché l'algoritmo va a ritroso
symbol_emitted = X[t+1]
probabilty_to_add = B[t+1] * A[i,j] * E[j, symbol_emitted]
probability = probability + probability_to_add
# aggiorniamo il valore della backward probability
# per lo stato i-esimo esaminato al tempo t
B[t,i] = probability
# calcoliamo la probabilità finale sommando tutti
# gli stati più vicini allo stato t, ovvero quelle
# a tempo t = 1 (in codice = 0)
backward_probability = 0
for i in range(0, k):
backward_probability = backward_probability + B[0,i]
return backward_probability
2.6 Learning
Il terzo problema è quello del learning e si divide in due scenari a seconda se la risposta esatta è nota o meno, ovvero se si conosce la sequenza di stati relativa alla sequenza di simboli in input.
2.6.1 Primo scenario: risposta esatta nota
Sia la sequenza di simboli per i quali la corrispondente sequenza nascosta di stati è nota . Siano i simboli distinti nell'alfabeto e gli stati finiti in , nella HMM . Definiamo:
- = numero di volte che la transizione dallo stato allo stato si presenta in .
- = numero di volte che lo stato s in emette il simbolo nella sequenza .
Si dimostra che i parametri che danno il massimo sono le matrici di transizione ed emissione le cui entry sono date da:
Tuttavia, pochi dati in input possono essere insufficienti per una stima corretta. Quindi è possibile ricadere nel problema dell'overfitting.
2.6.2 Secondo scenario: risposta esatta non nota
Dato che non si è a conoscenza della sequenza di stati, l'idea è quella di partire assegnando valori randomici alle matrici ed ed aggiornare i parametri del modello in base alla conoscenza che si ha in un certo momento. Viene ripetuto il processo sinché non si soddisfa un criterio di terminazione. Tale principio prende il nome di Expectation-Maximization (EM).
Expectation Maximization
Il principio si basa sui seguenti passi:
- Stimare e dai dati osservati utilizzando i valori correnti ed delle matrici di transizione ed emissione;
- Aggiornare i parametri delle matrici ed in base ad e ;
- Ripetere i primi due passi sino a che il processo non converge.
2.6.3 Algoritmo Baum-Welch
L'algoritmo di Baum-Welch è un algoritmo di tipo Expectation-Maximization. Definiamo: Data la sequenza di simboli , tale espressione esprime la probabilità a posteriori che lo stato e che lo stato successivo . Osserviamo il lattice associato:
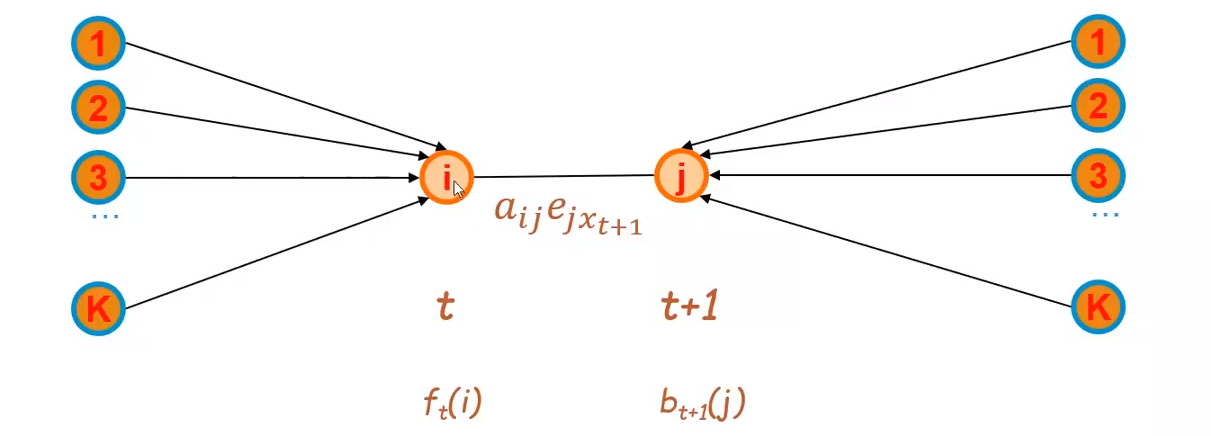
Possiamo calcolare la probabilità che si arrivi allo stato attraverso un percorso qualsiasi attraverso la probabilità forward, mentre calcoliamo la probabilità di arrivare al tempo tale che provenendo, al tempo , da uno qualunque dei stati attraverso la probabilità backward. È necessario considerare anche la transizione da a e l'emissione del simbolo . Essendo una probabilità, bisogna normalizzare il valore ottenuto tra 0 ed 1. È necessario quindi dividere il risultato per la somma di risultati ottenuti considerando la stessa espressione per ogni possibile coppia di stati . Introduciamo un'ulteriore quantita , ovvero la probabilità a posteriori di trovarsi al tempo nello stato : Possiamo stimare la probabilità di transizione come il rapporto tra il numero di volte in cui passiamo dallo stato allo stato ed il numero di volte in cui passiamo dallo stato ad un qualsiasi altro stato: Possiamo stimare la probabilità di emissione come il rapporto tra il numero di volte in cui dallo stato emetto il simbolo e il numero di volte in cui entro nello stato (emettendo un simbolo qualsiasi): I passi dell'algoritmo sono i seguenti:
- Inizializzazione:
- inizializza ed randomicamente (o in base ad una conoscenza pregressa)
- Iterazione
- Calcola le probabilità forward
- Calcola le probabilità backward
- Aggiorna i parametri del modello calcolando le stime e
- Calcola la probabilità di osservare la sequenza di simboli con i parametri
- Itera nuovamente sino a che varia poco rispetto al valore precedente
La probabilità è calcolabile banalmente poiché ricade nel problema dell'evaluation già affrontato.
L'algoritmo non garantisce di trovare i migliori parametri e può convergere a minimi locali in base alle condizioni iniziali. Sia b il numero di iterazioni, la complessità è .