Predizione
1. Introduzione
La predizione è simile alla classificazione poiché costruisce un modello e usa il modello per predire valori per un dato input. La predizione è diversa rispetto alla classificazione poiché la classificazione predice valori categoriali (etichette), mentre la predizione modella funzioni a valori continui.
Diversi classificatori possono essere utilizzati come predittori (alberi decisionali, SVM), e viceversa (regressione logistica). La tecnica più importante di predizione è la regressione.
2. Regressione
La regressione è una forma di apprendimento supervisionato che consente di apprendere una mappatura tra i dati di input e i corrispondenti output. Esempi di task legati alla regressione sono:
- Predizione del prezzo di prodotti date delle caratteristiche
- Predizione del profitto di una certa compagnia
- Contare il numero di automobili presenti in una immagine.
2.2 Definizione formale
Definiremo un regressore come una funzione dove è la dimensionalità del dominio (features dei dati in input) ed è la dimensionalità del codominio (features dei dati in output). In generale, ci riferiremo ad un dato in input con , all'output vero legato ad con e all'output predetto dal regressore con . Possiamo predire un valore a partire da : In questo contesto, spesso è chiamata variabile indipendente, mentre è chiamata variabile dipendente. Come visto nella classificazione, possiamo definire una funzione di rappresentazione per mappare un input da ad . Utilizzando la funzione di rappresentazione, possiamo predire il valore per un input : Per trovare la funzione di regressione possiamo utilizzare vari metodi a seconda del contesto. Vedremo la regressione lineare, la regressione lineare multipla, la regressione polinomiale e quella logistica.
2.3 Misure di performance
Sia il test set su cui validare il regressore. Definiamo: l'insieme degli output corretti (o etichette di ground truth), e: l'insieme di output predetti. Idealmente vorremmo che gli output predetti siano quanto più vicini agli output corretti (nel caso migliore ). Dal momento in cui gli elementi di entrambi gli insiemi sono vettori di egual dimensione, definiremo le misure di performance come misurazioni di vicinanza o verosimiglianza tra gli output predetti e gli output corretti.
2.3.1 Mean Squared Error (MSE)
Consideriamo per ogni elemento del test set la corrispondente etichetta di ground truth e l'etichetta predetta dalla funzione di regressione . Le etichette hanno dimensione , quindi una buona misura di vicinanza tra le due è spesso la distanza euclidea: Per risparmiare il tempo computazionale impiegato nel calcolo della radice quadrata, spesso si utilizza la distanza euclidea quadratica: A questo punto, l'MSE consiste nel calcolare l'errore medio per tutti gli input del test set:
2.3.2 Root Mean Squared Error (RMSE)
L'unità di misura dell'MSE è il quadrato dell'unità di misura della variabile dipendente (). Nella pratica, se è misurata in metri, l'errore MSE sarà misurato in metri quadrati . Per ovviare a questo possiamo utilizzare il root mean squared error (RMSE):
2.3.3 Mean absolute error (MAE)
Se le etichette sono scalari (), allora possiamo misurare l'errore e mantenere la stessa unità di misura attraverso il mean absolute error, ovvero la media delle differenze tra le etichette in valore assoluto:
2.3.4 Differenza tra MSE, RMSE e MAE
Tutte e tre le misure di performance sono misure di errore, per cui un buon regressore dovrebbe puntare a minimizzarle. La principale differenza tra gli indici presentati sta nel fatto che MSE e RMSE enfatizzano l'errore al crescere della distanza tra i punti, mentre tralasciano gli errori piccoli. Tuttavia, MAE risulta più intuitivo.
2.4 Casi speciali di regressione
Mentre la regressione può essere definita in maniera generale con una funzione: Vi sono alcuni casi molto frequenti in cui vi sono particolari valori di ed , noi vedremo i seguenti.
Regressione semplice La regressione semplice prevede che , per cui il task consiste nel mappare numeri scalari a numeri scalari con una funzione :
Regressione multipla La regressione multipla si ha quando ed , e consiste nel mappare vettori su scalari con una funzione :
Regressione multivariata La regressione multivariata è quella più generale, dove ed è arbitrario. Consiste nel mappare vettori o scalari (nel caso ) su vettori con una funzione :
3. Regressione lineare
Vedremo il metodo della regressione lineare applicata su casi di regressione semplice, multipla e multivariata.
3.1 Regressione lineare semplice
La regressione lineare semplice consiste nel trovare una funzione di forma . Per iniziare, consideriamo un esempio in cui il dataset consiste in coppie referenti:
- Il numero medio di stanze in una casa in un quartiere;
- Il prezzo medio delle case nel quartiere (misurato in , es. = )
Disegniamo un plot del dataset ponendo il numero medio di stanze sull'asse delle ed il prezzo medio sull'asse delle :
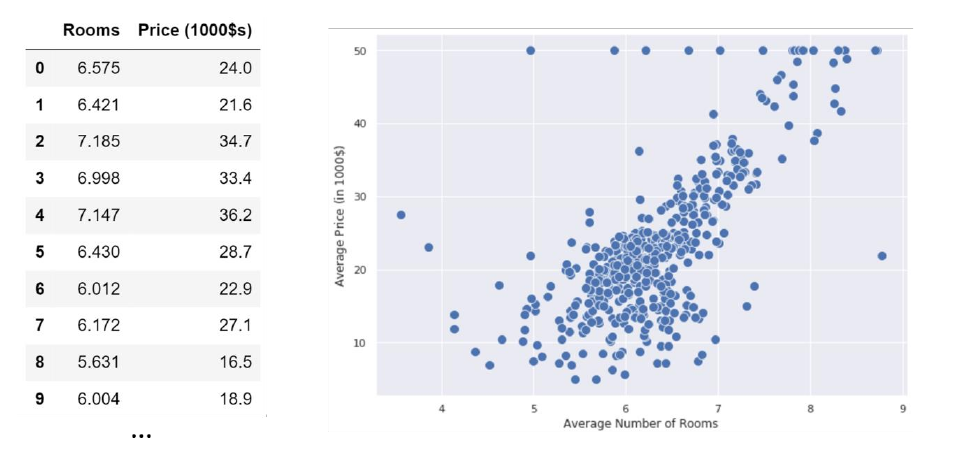
Vorremmo idealmente trovare una funzione che riesca ad approssimare il prezzo medio delle case dato un numero di stanze medio . Dal plot osserviamo che il prezzo aumenta proporzionalmente al numero di stanze. Calcolando la covarianza otteniamo , il che è un'altra conferma della correlazione tra le due variabili. Esse seguono circa un andamento lineare, quindi sono approssimativamente distribuite lungo una retta:
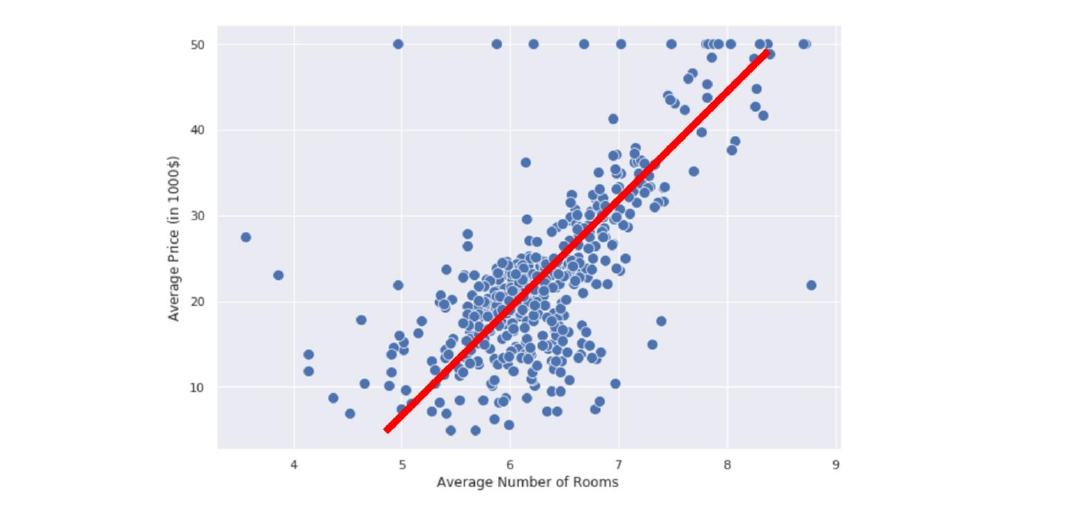
Possiamo quindi costruire la nostra funzione di regressione utilizzando la formulazione analitica di una retta: Dove è il coefficiente angolare e è l'intercetta. Anziché e utilizzeremo rispettivamente e . Tale notazione ci aiuterà a generalizzare la regressione al caso multiplo. Chiamiamo la funzione modello lineare o regressore lineare, dove e sono i parametri del modello. Allenare un modello lineare significa trovare quei valori nei parametri e tale che dia una buona predizione di . Vedremo due metodi per fare ciò: il metodo dei minimi quadrati e la discesa del gradiente.
Consideriamo il precedente esempio e immaginiamo che qualcuno abbia allenato il modello lineare e che i parametri siano e , per cui il nostro regressore lineare sarà così definito: Se proviamo a plottare la linea in figura, essa sarà quella retta con maggiore densità lineare e avrà, nel caso migliore, una misura di errore bassa.
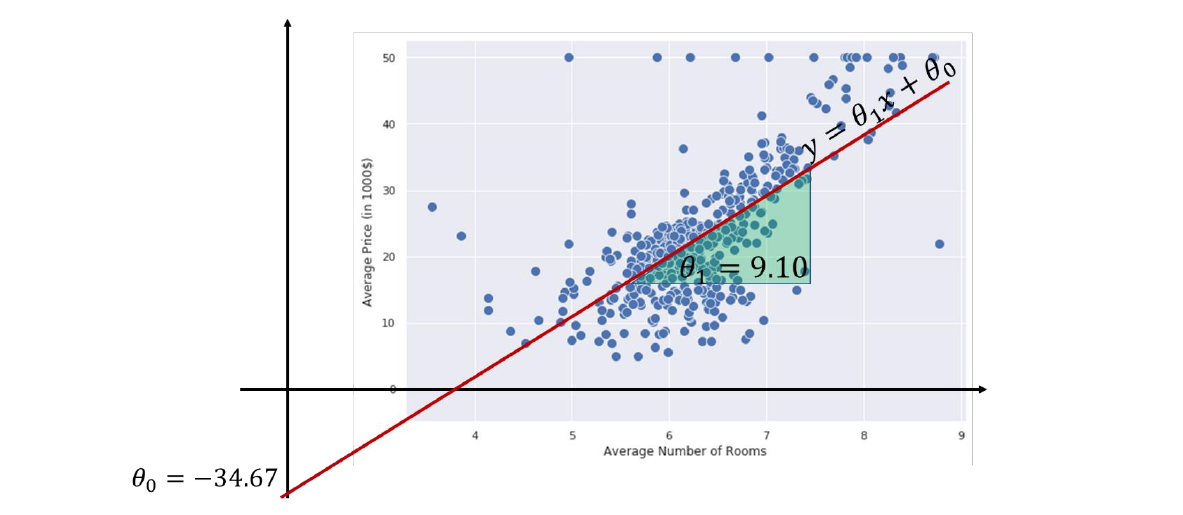
3.2 Interpretazione geometrica
Sappiamo che i valori hanno un ben preciso significato geometrico:
- è l'intercetta: esprime la posizione di nello spazio, ovvero dove intercetta la retta quando .
- è il coefficiente angolare: esprime l'orientamento di rispetto all'asse .
In generale, i due coefficienti hanno specifici effetti geometrici. Rispetto al coefficiente angolare:
- Un valore alto di da luogo a curve più ripide;
- corrisponde ad una retta orizzontale, quindi parallela all'asse delle ;
- rappresentano rette "all'indietro";
Rispetto all'intercetta:
- Il valore decide dove sta la retta nello spazio;
- Valori alti di spingono sopra la retta, per cui si hanno valori alti di (e viceversa)
3.3 Interpretazione statistica
Dall'interpretazione geometrica possiamo tirar fuori alcune considerazioni statistiche:
-
L'intercetta è il valore che si ottiene quando l'input è nullo: .
-
Il coefficiente angolare indica la ripidità della retta: rette più ripide indicano che piccole variazioni su riflettono grandi variazioni su , di fatti possiamo osservare la dipendenza diretta da: Ciò implica che quando osserviamo un incremento di 1 unità su , si riflette un incremento di unità su y.
3.4 Correlazione contro causa
Dovremmo sempre attenzionare l'interpretazione dei coefficienti di un regressore lineare. Un regressore cattura la correlazione tra le variabili indipendenti, ma non ne spiega il perché. Ciò implica che, se l'incremento di una unità su una variabile indipendente si riflette in un aumento di un numero di unità nella variabile dipendente, non dovremmo stabilire nessun tipo di correlazione formale, poiché stiamo solo osservando l'avvenimento di due fenomeni in contemporanea.
3.5 Regressione lineare multipla
Possiamo facilmente estendere la regressione lineare semplice al caso della regressione lineare multipla. Cerchiamo adesso una funzione definita come . In tal caso dovremmo trovare un parametro per ognuna delle dimensioni della variabile in input, più un parametro per l'intercetta: I parametri sono quindi . Allenare il regressore significa trovare un insieme di parametri appropriato per prevedere i valori con migliore accuratezza raggiungibile. La funzione sarà quindi in generale un iperpiano ad dimensioni.
Per convenzione e semplicità di espressione, poniamo e scriviamo il modello lineare come segue: Cosicché l'intercetta sia moltiplicata ad 1, e quindi non vari.
Consideriamo un esempio in cui , nel quale si vuole predire il prezzo di una casa in un quartiere a partire dal numero medio di stanze e dal tasso di criminalità nel quartiere.
Essendo la somma delle dimensioni uguale a 3, possiamo visualizzare un plot tridimensionale dei nostri punti:
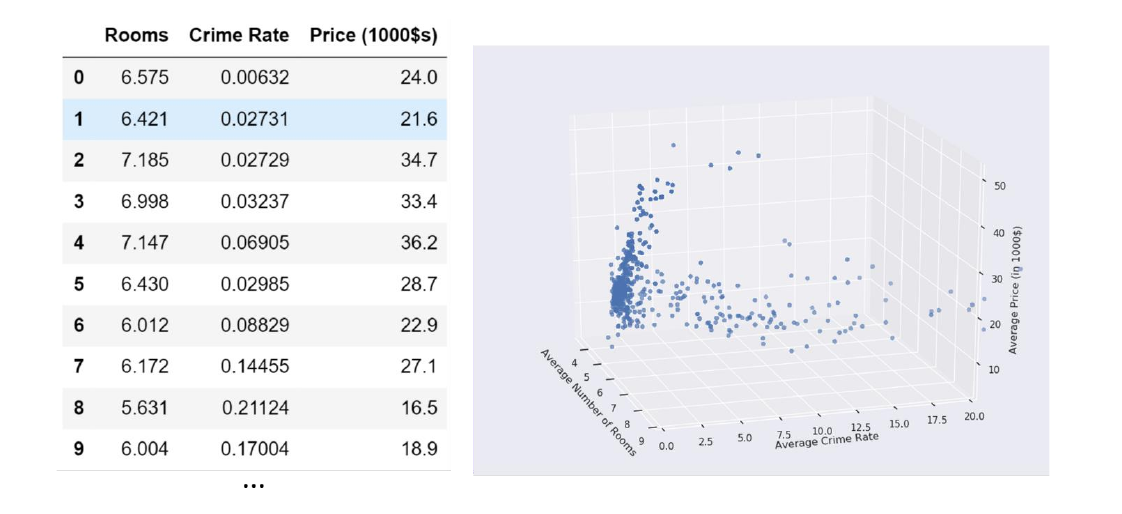
In tal caso il modello lineare sarà: Assumiamo che il modello sia già stato allenato e che i parametri siano i seguenti: Tali parametri identificano il piano nello spazio che meglio approssima la relazione tra i valori in input ed il prezzo da predire:
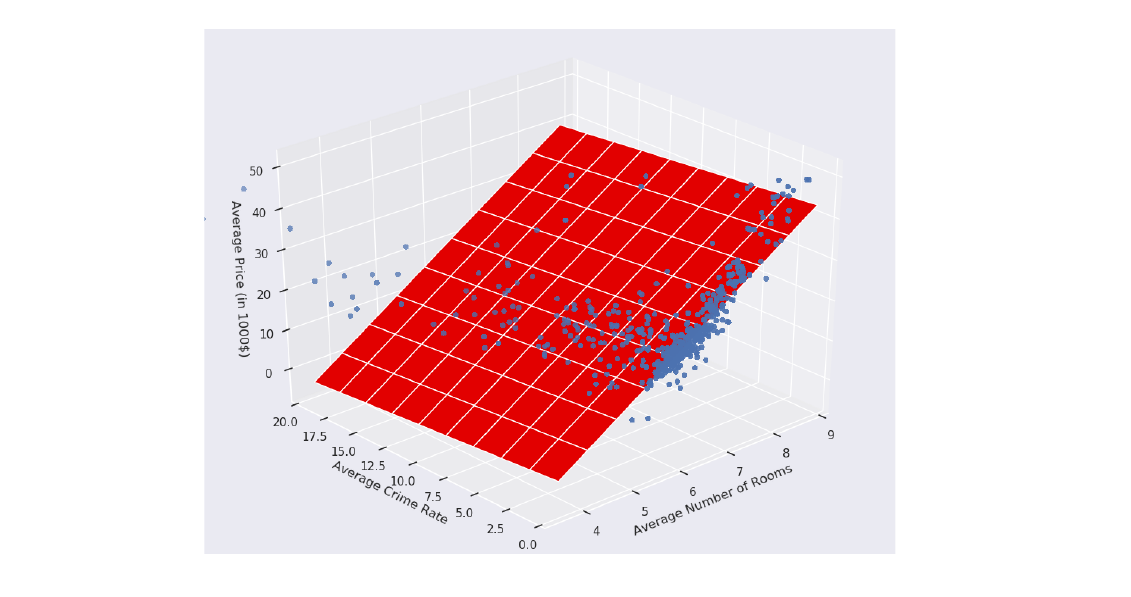
Allo stesso modo possiamo tirar fuori dei significati geometrici e statistici dai coefficienti:
- è il valore di quando tutte le (per non nulla);
- Osserviamo un incremento di unità quando l'i-esima dimensione aumenta di una unità e le altre restano costanti.
3.6 Regressione lineare multivariata
Consideriamo l'ultimo caso, ovvero quello della regressione lineare multivariata. Si cerca una funzione definita come . Il metodo della regressione lineare multivariata risolve il problema definendo regressori multipli indipendenti, uno per ogni dimensione dell'etichetta in output, che processano gli stessi input con pesi differenti: Ognuno dei regressori ha il proprio insieme di parametri , calcolati ed ottimizzati in maniera indipendente dagli altri regressori.
4. Il problema dell'apprendimento
Per capire come tirar fuori i parametri dal regressore ci concentreremo sul caso della regressione multipla, più generico rispetto alla regressione lineare e che pone le fondamenta per quella multivariata. Avremo quindi un regressore : Dove indica il fatto che il regressore dipenda dai parametri . Allenare il regressore significa lasciare che il regressore apprenda quali siano i parametri che minimizzino l'errore di predizione nel training set . Possiamo quantificare l'errore attraverso una funzione costo: Osserviamo che l'espressione sopra è l'indice MSE calcolato sul training set per una certa configurazione di parametri , a meno di una differenza nel prima fattore, che risulta essere anziché . Questa scelta risulterà conveniente in futuro nel metodo della discesa del gradiente. Vorremmo idealmente che la funzione costo sia prossima zero. Di conseguenza, una buona scelta di è quella che minimizza la funzione :
4.1 Metodo dei minimi quadrati
Prima di passare al metodo della discesa del gradiente, vediamo un metodo leggermente più statistico e diretto, il metodo dei minimi quadrati (least squares method). Supponiamo di trovarci nel caso della regressione semplice, per cui:
Il metodo fornisce delle formule dirette per trovare i coefficienti della retta che meglio approssima l'andamento dei punti:
Dove e sono i valori medi. È possibile estendere il metodo dei quadrati minimi per la regressione polinomiale, ma non affronteremo questa tematica.
4.2 Algoritmo di discesa del gradiente
Abbiamo letto nel problema dell'apprendimento che l'insieme di parametri assunti dal modello deve minimizzare la funzione costo . Un approccio naïve potrebbe suggerire di provare tutte le possibili combinazioni di , ma essendo un numero massivo risulta subito un cattivo approccio.
Per risolvere tale problema si possono utilizzare molte strategie di ottimizzazione: quella che utilizzeremo prende il nome di algoritmo di discesa del gradiente, il quale permette di minimizzare qualsiasi funzione differenziabile rispetto ai propri parametri.
4.2.1 Esempio ad una variabile
Supponiamo di avere una funzione convessa come in figura, ovvero una funzione con un solo minimo locale.
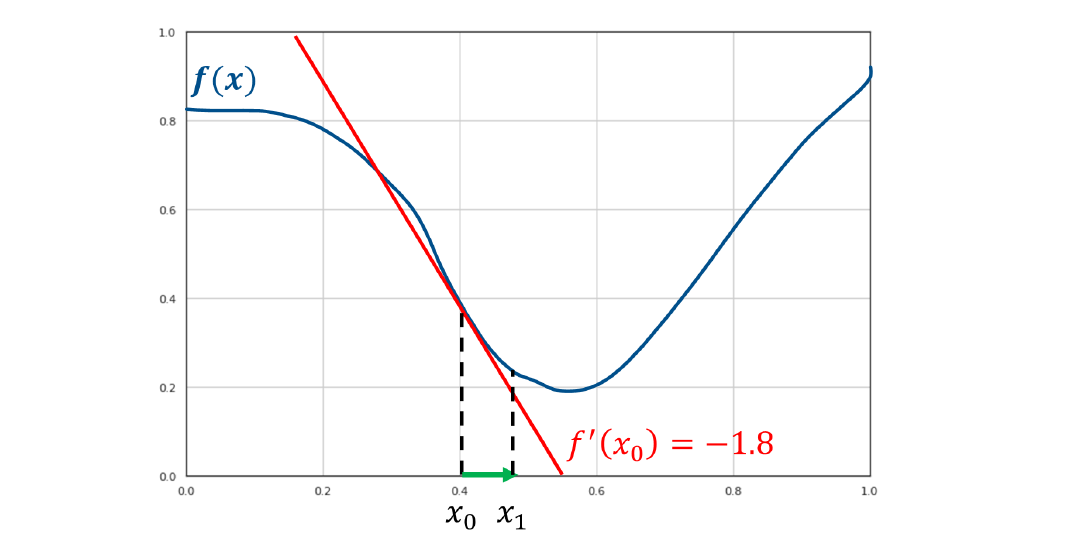
Supponiamo di partire da un punto qualsiasi, per trovare il minimo bisogna seguire l'andamento decrescente della funzione. Tuttavia non abbiamo abbastanza informazioni per sapere come muoverci, quindi è necessario utilizzare uno strumento matematico che dia informazioni sull'andamento della funzione: la derivata.
La derivata fornisce la pendenza (coefficiente angolare) della retta tangente al punto in cui viene calcolata. Di fatto, la retta tangente ci comunica in che direzione la funzione aumenta o diminuisce nell'intorno del punto.
Se il coefficiente angolare è positivo, allora la retta è crescente nel verso dell'asse delle , e quindi lo è anche la funzione, per cui allo scopo di trovare il minimo è necessario muoversi verso sinistra. Viceversa nel caso in cui si ottienga un coefficiente angolare negativo.
Nella funzione d'esempio la derivata ha coefficiente angolare negativo, per cui la funzione è decrescente nel punto e conviene prendere il prossimo punto verso destra, di fatto ma .
La direzione corretta per trovare il minimo è la direzione inversa alla tangente ottenuta attraverso la derivata.
L'algoritmo di discesa del gradiente è un algoritmo iterativo che si sposta nella direzione decrescente della funzione sino a trovare il minimo, ovvero quando la derivata risulta nulla. Ma di quanto ci muoviamo lungo l'asse delle ad ogni step?
Ad ogni step ci muoveremo sull'asse delle proporzionalmente al valore della derivata. Tale euristica è basata sull'osservazione che valori maggiori, in valore assoluto, della derivata indicano pendenze più ripide, quindi si è probabilmente più lontani dal minimo. Scegliendo una costante chiamata learning rate, ci muoveremo ad ogni step nel seguente modo: Osserviamo che, come sperato, se la derivata è negativa, ci muoveremo verso destra di un fattore , viceversa per la derivata positiva. Vediamo come procede l'algoritmo nel nostro esempio di prova:
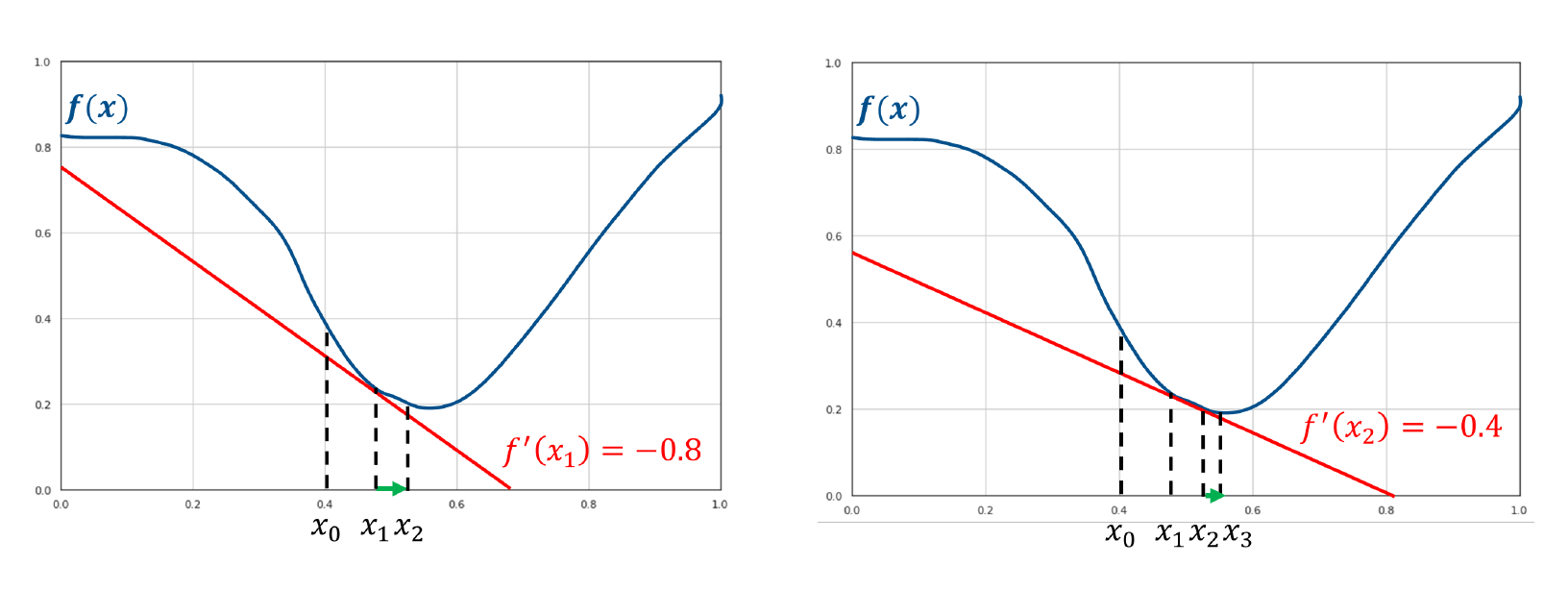
Nel punto la derivata è così vicina allo 0 che approssima quasi perfettamente il minimo. Per cui soddisfa l'espressione: Nella pratica, l'algoritmo finisce la sua iterazione in due casi:
- Un numero massimo di iterazioni è stato raggiunto;
- Il valore è al di sotto di una data soglia.
Nel caso di una variabile, possiamo riassumere l'algoritmo attraverso il seguente pseudocodice:
def gradient_descend():
g = get_learning_rate()
max_loops = get_max_loops()
t_threshold = get_termination_threshold()
x = random()
loops = 0
while (x > t_threshold && loops < max_loops):
m = f'(x)
x = x - (g * m)
return x
4.2.2 Caso multivariato
L'algoritmo di discesa del gradiente è generalizzato nel caso in cui la funzione da ottimizzare sia a più variabili . Per funzioni a più variabili, anziché la derivata è necessario considerare il gradiente, da cui il nome dell'algoritmo.
Il gradiente è una generalizzazione della derivata per funzioni a più variabili.
Il gradiente di una funzione ad variabili in un punto è un vettore la cui -esima componente è data dalla derivata parziale della funzione rispetto alla -esima variabile calcolata nel punto : Nel caso in cui la funzione sia a due variabili, si potrebbe costruire un plot tridimensionale come segue. In tal caso, il gradiente sarà un vettore a due dimensioni e varierà punto per punto.
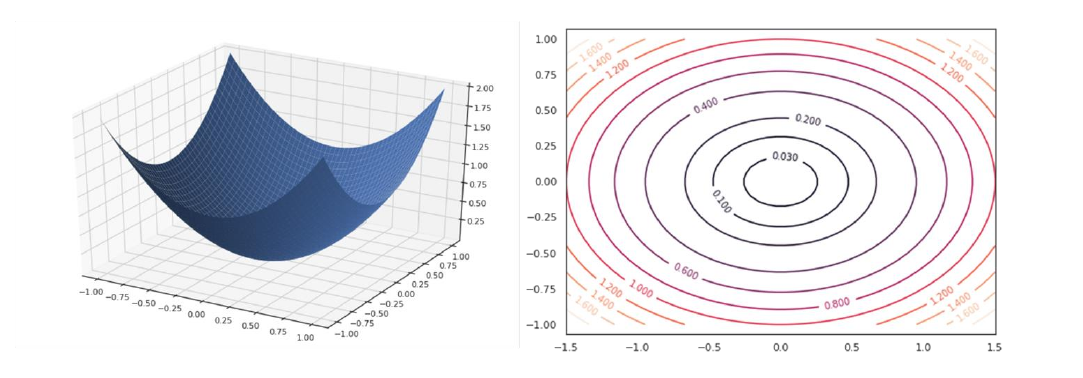
La figura che segue mostrerà graficamente l'andamento che deve seguire la procedura nel caso multivariato:
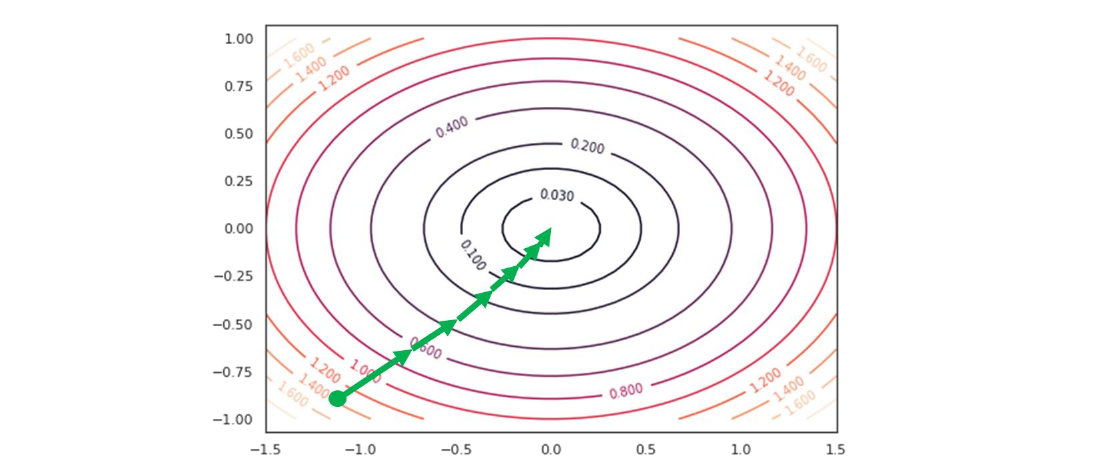
Il ragionamento è analogo, ma l'aggiornamento dei pesi va fatto per ogni variabile. Di conseguenza i passi che seguirà l'algoritmo sono i seguenti:
-
Inizializzare in maniera randomica
-
Per ogni variabile :
- Calcolare la derivata parziale nel punto :
- Aggiornare utilizzando la formula precedente:
-
Ripetere i primi due passi sino a soddisfarre un criterio di terminazione.
4.3 Discesa del gradiente e regressione lineare
Utilizzeremo l'algoritmo di discesa del gradiente per risolvere il problema di ottimizzazione della regressione lineare, quindi per trovare i coefficienti ottimali : Il primo passo è quindi inizializzare randomicamente e applicare iterativamente la regola di aggiornamento per ogni variabile: È necessario quindi calcolare la derivata parziale rispetto a ciascuno dei parametri in input. Scriviamo prima la funzione costo nei termini dei parametri : Esplicitandolo: Dove ricordiamo che per convenzione.
Possiamo calcolare facilmente la derivata parziale di questa funzione rispetto alla -esima componente : Ma notiamo che: Quindi sostituendo e semplificando otteniamo che: La regola di aggiornamento può essere scritta come segue: Con la regola di aggiornamento abbiamo tutto ciò che ci serve per implementare l'algoritmo computazionalmente, utilizzando criteri di terminazione basati sul numero di iterazioni o sulla soglia di aggiornamento.
4.4 Considerazioni sul learning rate
Il learning rate è un iperparametro da determinare. Possiamo utilizzare un validation set per effettuare delle prove e selezionare il valore con risultati migliori. Alcune considerazioni sul learning rate sono:
- Un learning rate basso converge più lentamente ma con buona precisione.
- Un learning rate alto converge più velocemente ma con una precisione peggiore. Può inoltre capitare una situazione di stallo in cui si salta continuamente da un punto a tangente crescente ad un punto a tangente decrescente, generando un effetto ping pong.
5. Regressione non lineare
La regressione lineare risulta limitante nei casi in cui la relazione tra le variabili indipendenti e la variabile dipendente è chiaramente non lineare. Consideriamo ad esempio il seguente plot:
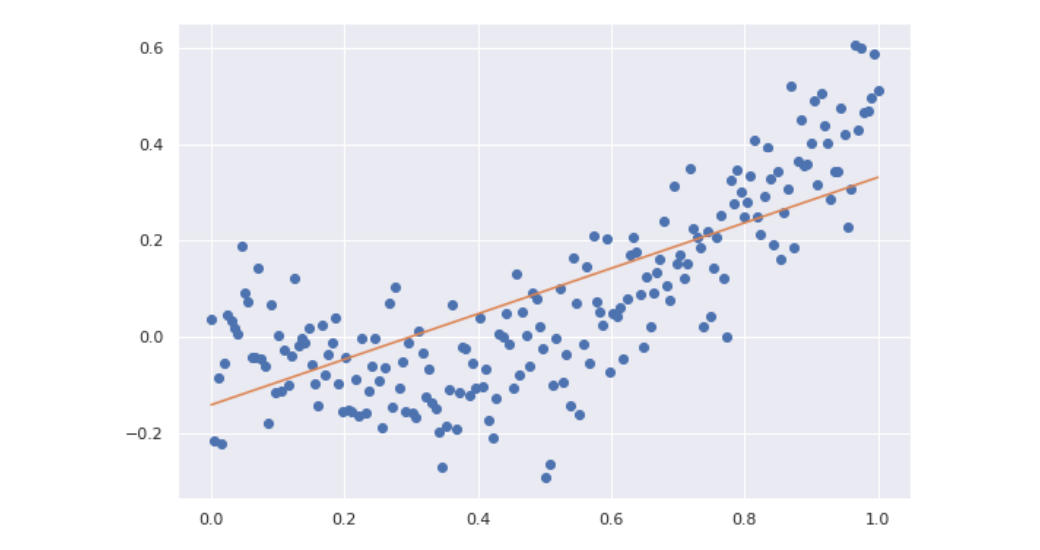
La relazione tra le variabili segue chiaramente una curva anziché una retta. Utilizzare la regressione lineare produrrebbe sicuramente fenomeni di underfitting.
5.1 Regressione polinomiale
Anziché utilizzare una funzione lineare , potremmo introdurre parametri addizionali e utilizzare una funzione polinomiale come segue: Dove rappresenta la potenza -esima di e non l'indice rispetto al training set. Modelli polinomiali di grado più alto consentono di rappresentare funzioni non lineari:
Più alto è il grado del polinomio, più si possono ottenere curve complesse. Possiamo facilmente osservare che anche se la funzione non è lineare rispetto ad , essa è lineare rispetto alle variabili . Determinate le variabili , trovare i coefficienti è comunque un problema di regressione lineare, risolvibile attraverso l'algoritmo di discesa del gradiente.
Osserviamo che possiamo trasformare un problema di regressione lineare in uno polinomiale replicando volte lo scalare e prendendo progressivamente le potenze sino al grado . Se allora: Se applichiamo questo metodo all'esempio precedente con un grado avremo un risultato di gran lunga più adatto rispetto ad una retta;
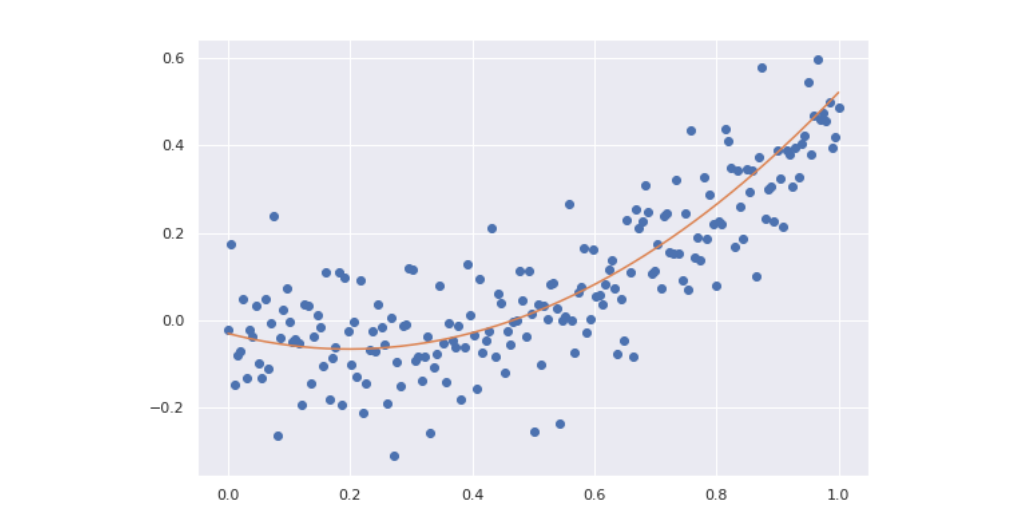
5.1.1 Regressione polinomiale a più variabili
Se la regressione prevede più attributi in input, ripetiamo il processo per ognuno degli attributi ed aggiungiamo anche i termini di interazione. Ad esempio, se la dimensione dell'input è 2 e si decide di polinomizzare la funzione aggiungendo gradi, allora i coefficienti totali saranno : È possibile ottenere i termini attraverso il teorema multinomiale. A causa della presenza dei termini di interazione, all'aumentare delle feature in input il numero di coefficienti da calcolare aumenta in maniera massiva e la computazione diventa onerosa. Se si effettua la regressione polinomiale con un grado molto alto è possibile incappare nel problema dell'overfitting.
Dal punto di vista procedurale, il modo più semplice per implementare la regressione polinomiale consiste nel dare in pasto ad un regressore lineare il numero finale di feature. Anziché costruire un regressore polinomiale per degli input che esegua la polinomizzazione al grado , potremmo (supposto ) utilizzare un regressore lineare mappando gli input originali ed ottenere lo stesso risultato.
5.1.2 Regolarizzazione
Limitando il grado della regressione polinomiale è possibile ridurre il rischio di overfitting. Tuttavia, a volte non si vuole rinunciare alla flessibilità di un polinomio di alto grado. Supponiamo che il problema di predizione sia risolto da un polinomio di grado 3, il cui secondo termine è mancante Il modello privato del secondo termine ha ridotto la propria capacità (meno coefficienti da calcolare) rispetto al modello che prende in considerazione i termini di ogni grado: Tale problema non può essere approssimato con un polinomio di secondo grado: Quindi utilizzeremo la prima soluzione, ponendo fissato. Computazionalmente è difficile determinare quale parametro deve essere posto a 0 per approssimare al meglio la soluzione del problema.
In generale esiste un rapporto tra la norma dei coefficienti di una funzione polinomiale e la sua flessibilità (e quindi capacità). Nel grafico sottostante vediamo tre polinomi i cui coefficienti sono proporzionali tra loro a meno dell'intercetta, scelta ad hoc per posizionare le funzioni vicine tra loro lungo l'asse . Il polinomio verde risulta visivamente meno flessibile, e concorde alla osservazione, i coefficienti sono più piccoli rispetto a quelli degli altri due polinomi.
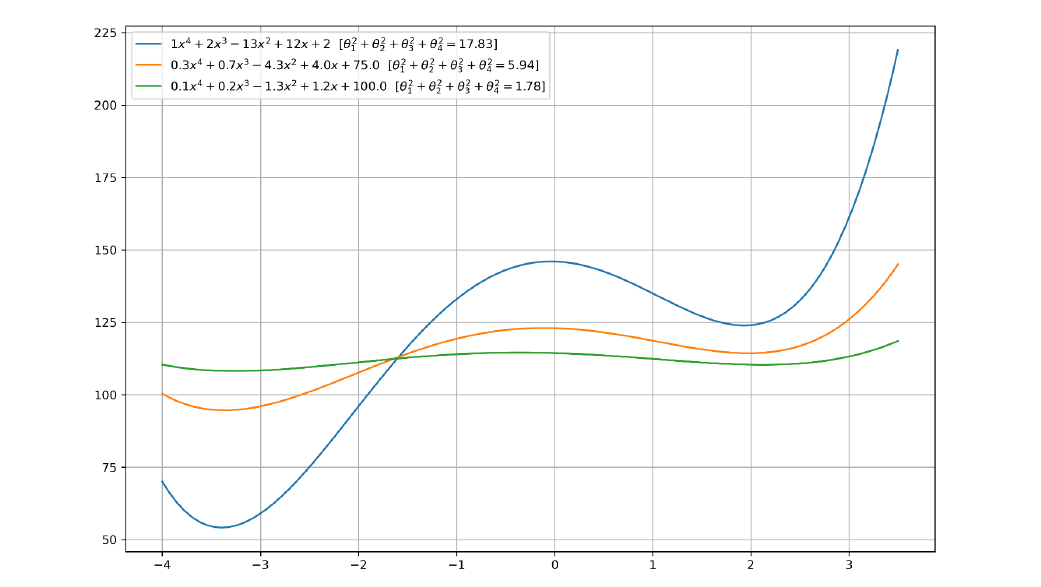
5.1.3 Termine di regolarizzazione
Se preferiamo trovare soluzioni meno flessibili per limitare la possibilità di overfitting, potremmo aggiungere alla funzione costo da minimizzare un certo termine, chiamato termine di regolarizzazione, che fornisce una misura di grandezza per i coefficienti del polinomio.
Il termine di regolarizzazione deve crescere proporzionalmente ai coefficienti, per cui possiamo utilizzare una semplice somma di quadrati: Il processo per cui la funzione costo viene modificata aggiungendo il termine di regolarizzazione per bilanciare la grandezza dei coefficienti è chiamato regolarizzazione. La funzione costo è ri-definita come segue: Dove il valore serve a bilanciare quanto la grandezza dei coefficienti influenzi la scelta dei coefficienti stessi. È un iperparametro da determinare attraverso un validation set. Questo tipo di regolarizzazione prende il nome di regolarizzazione L2 poiché il termine di regolarizzazione non è altro che la norma L2. Il tipo di regressione considerata prende il nome di Ridge regression.
5.1.4 Decadimento del peso
La nuova funzione costo è ancora differenziabile rispetto ai parametri , il che è fondamentale per l'implementazione di un algoritmo di discesa del gradiente. Lo step di aggiornamento sarà adesso: Notiamo che: Per cui scriviamo lo step di aggiornamento come segue: L'aggiornamento è analogo al precedente a meno di un fattore penalizzante , Questa regolarizzazione è anche chiamata decadimento del peso (weight decay) per indicare che i coefficienti (pesi) debbano decadere con il tempo per limitare la crescita.
6. Regressione logistica
Un regressore lineare multiplo permette di associare un numero reale ad un vettore in input attraverso una funzione parametrica . L'obiettivo di un classificatore è simile: predire una classe a partire da un vettore in input . Vedremo come è possibile costruire una funzione parametrica che possa performare la classificazione .
6.1 Limiti della regressione lineare per la classificazione
Ci concentreremo sul task della classificazione binaria per iniziare, quindi avremo due sole classi . Potremmo provare ad utilizzare la regressione lineare per predire direttamente la classe binaria: Tuttavia questo metodo risente di alcuni problemi fondamentali. Consideriamo un esempio ad una dimensione in cui degli input sono classificati in due classi :
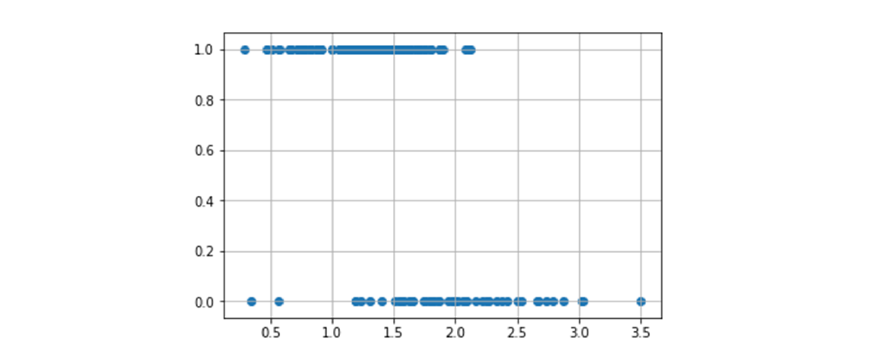
Idealmente vorremmo una funzione che associ tutti i punti "positivi" ad 1 e tutti i punti "negativi" a 0. Tale funzione sarebbe definita come , quindi il codominio sarà discreto. Se proviamo ad utilizzare la regressione lineare, otterremo con molta probabilità una linea del genere:
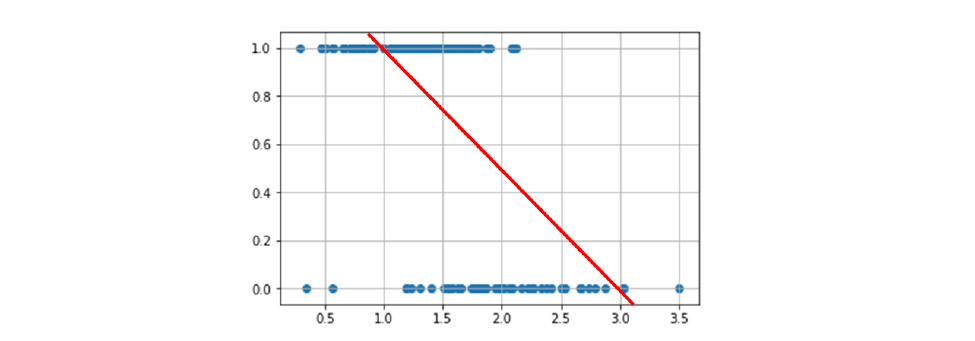
Possiamo vedere immediatamente che tale funzione non risultà essere particolarmente accurata nella classificazione: cosa fare quando i punti stanno nel mezzo? O quando stanno sopra 1 / sotto 0? Potremmo migliorare la funzione mappando gli input alla probabilità che essi assumano il valore 1: . La funzione sarebbe definita come segue: , che risolve i problemi sull'assegnazione dei valori tra 0 ed 1, ma risulta ancora imprecisa per input fuori dal range. Anziché una retta, vorremmo utilizzare una curva ad che copra gli elementi come segue:
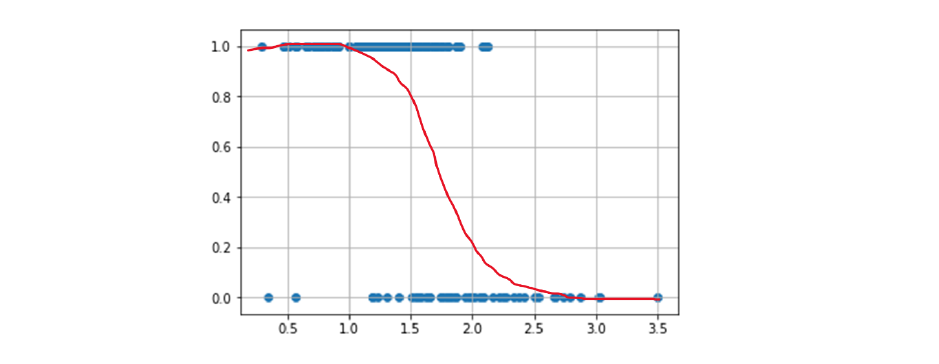
Questa funzione ideale mappa gli input nel range e satura a ed , il che è naturale poiché all'avvicinarsi ad uno dei due estremi densi aumenta anche la certezza di appartenenza ad una classe. Questa analisi suggerisce che non è possibile risolvere il problema della classificazione attraverso una funzione lineare.
6.2 Funzione dispari e Logit
Vorremmo trovare una trasformazione della probabilità che mappi i valori da a e che renda possibile l'approssimazione delle probabilità attraverso una funzione lineare.
Sia la probabilità che un esempio sia positivo. Considereremo la funzione dispari (odd function) di la misura della proporzione tra probabilità che l'esempio sia positivo e quella che l'esempio sia negativo: Questa prima trasformazione risolve parte del problema, di fatto mappa la probabilità dall'intervallo all'intervallo ). Vediamo l'effetto della mappatura nel grafico sottostante:
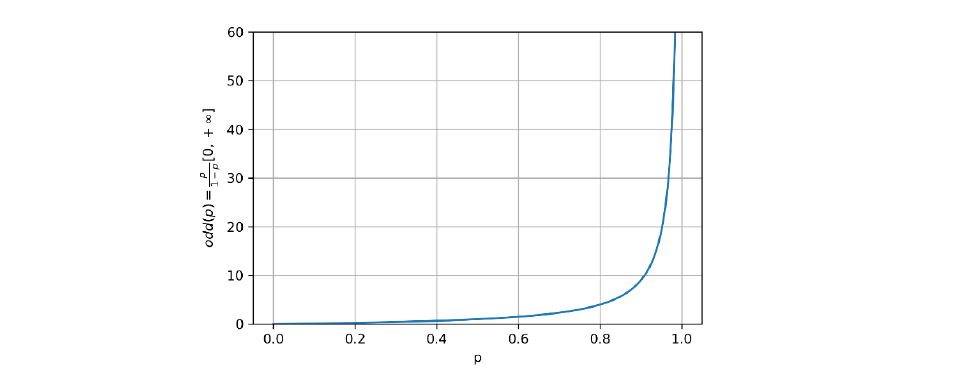
Vogliamo che l'intervallo finale sia , per cui definiamo la funzione logit come il logaritmo naturale della funzione dispari: Osserviamo che: altresì confermato dal grafico della funzione:
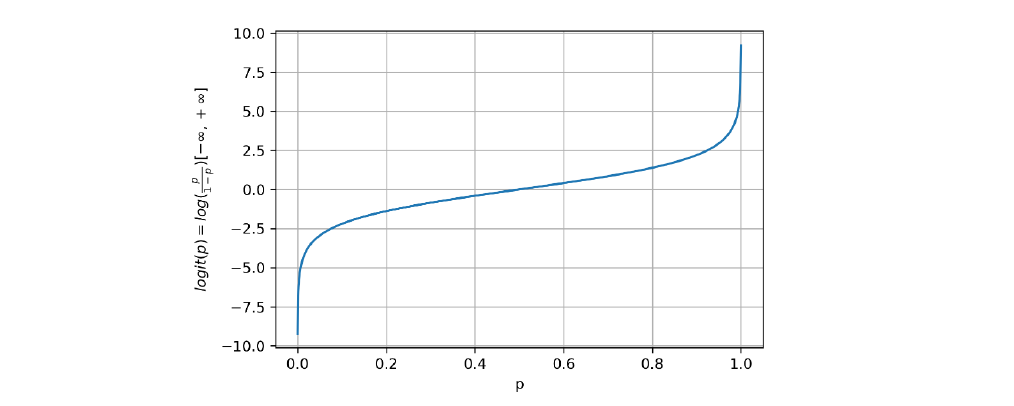
Ci si aspetta che le probabilità siano pressoché non lineari (a forma di ), la funzione di logit permette di linearizzare i dati rispetto all'asse , come mostrato in figura:
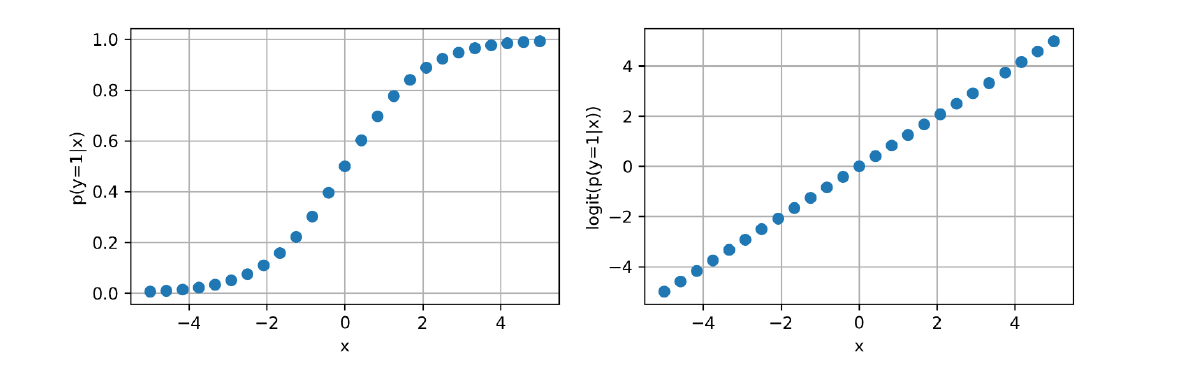
6.3 La funzione logistica
Adesso che la funzione logit mappa le probabilità in uno spazio in cui si dispongono linearmente, possiamo utilizzare un regressore lineare per trovare una retta che approssimi la funzione: Una volta trovati i coefficienti per il regressore lineare, dobbiamo trovare il metodo per estrapolare la probabilità dai risultati della funzione logit, quindi effettuare una mappatura inversa a quella iniziale: .
Possiamo farlo invertendo la funzione logit come segue:
- partiamo dalla espressione iniziale:
- utilizziamo l'esponenziale:
- moltiplichiamo entrambi i termini:
- semplifichiamo:
- raccogliamo per la probabilità:
- estraiamo la probabilità: Possiamo effettuare ulteriori semplificazioni una volta estratta la probabilità: La funzione derivata prende il nome di funzione logistica o funzione sigmoide ed è definita in generale come segue: La curva disegnata dalla funzione logistica è a forma di (da cui il nome sigmoide) come mostrato in figura:
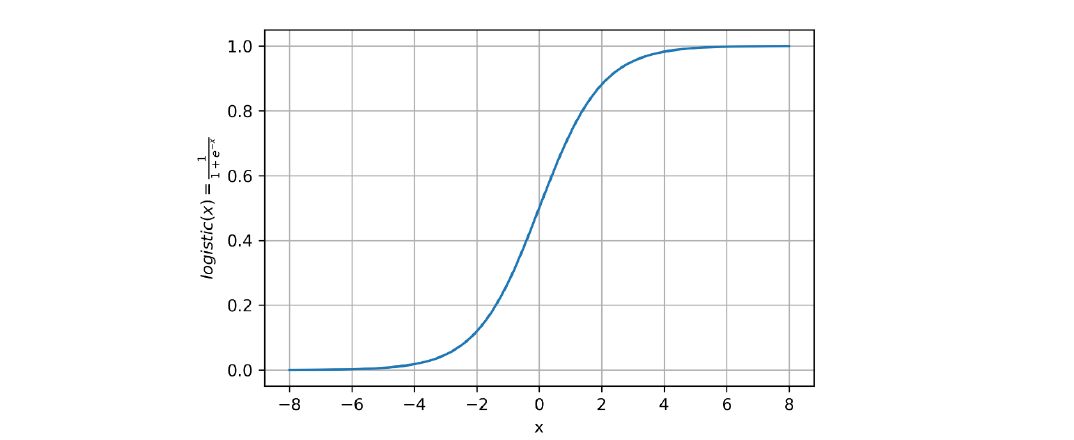
6.4 Il modello di regressione logistica
Possiamo finalmente definire il regressore logistico con la seguente funzione: Allenare il regressore logistico significa trovare i parametri che riescano ad approssimare al meglio la probabilita . La funzione approssimata non è più una retta, bensì un sigmoide:
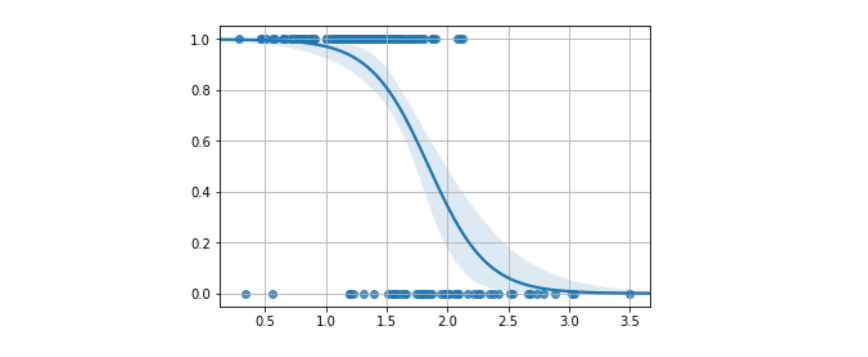
Una volta che il modello è allenato, possiamo classificare le osservazioni attraverso la seguente regola:
6.4.1 Funzione costo
Per allenare il modello definiremo una funzione costo, similmente a come fatto per la regressione lineare. Problema: il dataset fornisce degli input e degli output , questi ultimi sono interpretabili in termini probabilistici e non come risultati della funzione logistica, quindi non è possibile utilizzare direttamente la funzione costo del regressore lineare e stimare una retta.
Dalla definizione: Scriviamo: Per denotare l'utilizzo di un insieme di parametri . O nella versione compatta: Osservando che verrà preso in considerazione solo uno dei fattori a seconda se o . Possiamo stimare i parametri massimizzando la likelihood: Se assumiamo che tutte le osservazioni del training set sono indipendenti, allora la likelihood potrà essere espressa come segue: Massimizzare tale espressione è analogo a massimizzare il logaritmo negativo della likelihood (negative log likelihood, nll): Definiremo la funzione costo :
6.4.2 Applicare la discesa del gradiente
Possiamo ottimizzare la funzione costo del regressore logistico attraverso l'algoritmo di discesa del gradiente. Per farlo, è necessario applicare una funzione di aggiornamento del genere: È necessario quindi calcolare la derivata parziale della funzione costo . Si lascia allo studente volenteroso la derivazione, che risulta essere: Dove indica la funzione sigmoide (o logistica): Per cui il passo d'aggiornamento sarà esplicitato come segue: Osserviamo che il passo di aggiornamento è analogo a quello della regressione lineare a meno della funzione rimpiazzata con la funzione sigmoide .
6.4.3 Interpretazione geometrica
A differenza della regressione lineare multipla, che trova l'iperpiano che approssima al meglio i dati, la regressione logistica trova l'iperpiano che separa al meglio i dati. Come vediamo nell'esempio bidimensionale.
Ipotizziamo di allenare un regressore logistico con i seguenti dati: Supponiamo che l'insieme di coefficienti risultante sia il seguente: Per capire come i dati sono classificati analizziamo il caso di massima incertezza, ovvero quando la probabilità risultate è del 50% per ambo le classi: Se esplicitiamo l'ultima equazione otteniamo: Per cui il coefficiente angolare è e l'intercetta è . Se grafichiamo questa linea, otteniamo il confine decisionale tra gli elementi delle due classi.
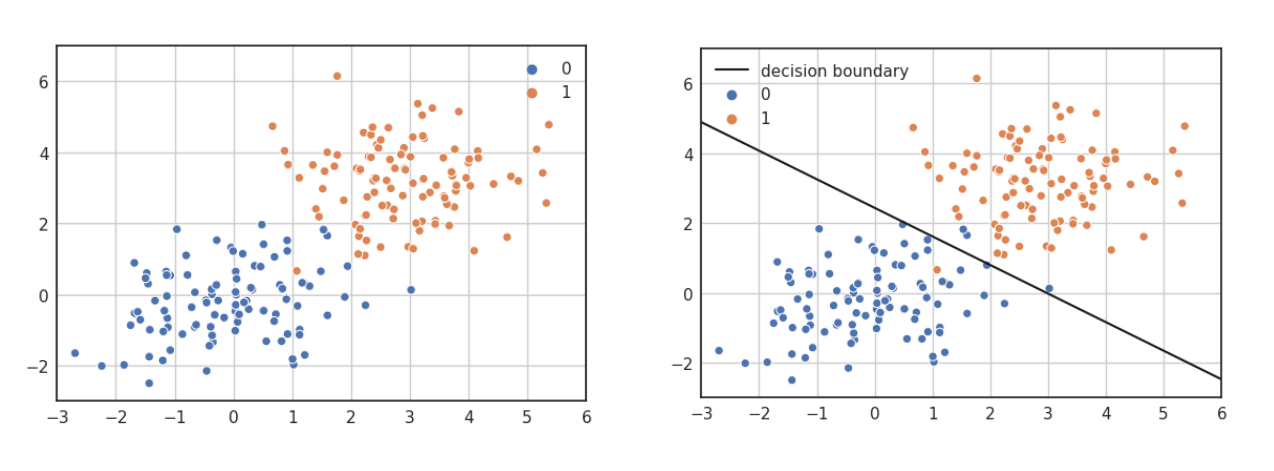
* L'iperpiano rappresentato è dato dai coefficienti e non rappresenta la funzione logistica, che non è una retta, bensì una curva.
6.4.4 Estensione al caso multiclasse: metodo one-vs-all
È possibile estendere il metodo della regressione logistica attraverso varie tecniche, tra cui la one vs all, la one vs one e la softmax regression. Vedremo in particolare come funziona la one vs all.
L'approccio one-vs-all permette di trasformare il problema della classificazione multiclasse (con più di 2 classi) in un insieme di problemi di classificazione binaria. Ogni sottoproblema può essere risolto attraverso un classificatore binario (es. il regressore logistico). Oltre al classificatore binario, è necessario che l'output contenga anche un valore di confidenza (confidence value), come un probabilità. Questo è necessario per confrontare i risultati di tutti i classificatori e capire quale potrebbe essere quello corretto.
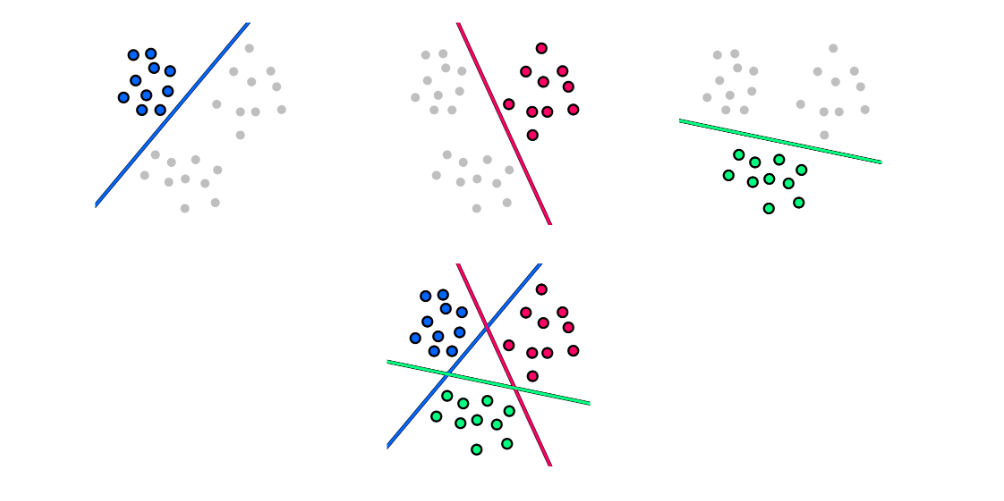
Dato un problema di classificazione con classi, l'approccio one-vs-all consiste nei seguenti passi:
- Dividere in task di classificazione binaria , dove si considera la classe contro tutte le altre.
- Allenare i classificatori separatamente.
- Per classificare un input utilizziamo ognuno dei classificatori , poi assegniamo la classe del classificatore con il confidence value maggiore.