4. Sistemi avanzati di raccomandazione
È possibile trovare una introduzione ai sistemi di raccomandazione nel testo Dive Into Data Mining.
4.1 LSI - Latent Semantic Indexing (LSI)
Il LSI è una tecnica sviluppata nei primi anni '90 che risolve il problema della sparsità e scalabilità per grandi dataset nel contesto semantico. Consiste principalmente nel ridurre la dimensionalità e catturare le relazioni latenti su matrici termini-documenti. Questa tecnica di indicizzazione utilizza la decomposizione SVD per identificare pattern nella relazione tra termini e concetti contenuti nel testo: si basa sul principio che parole utilizzate nello stesso contesto tendono ad avere significato simile.
4.1.1 LSI per sistemi di raccomandazione
È possibile applicare la tecnica LSI nel contesto dei sistemi di raccomandazione:
- La matrice termini-documenti sarà sostituita con la matrice di utilità
- Le categorie degli item prenderanno il posto dei concetti
- Il mapping , diviene ,
Quindi si calcola la SVD della matrice : Dalle proprietà della SVD sappiamo che le matrici e sono matrici dense.Sia il vettore contenente tutte le valutazioni effettuate dall'utente sugli item, supponendo che se l'utente non ha valutato l'item , allora . Calcoliamo dove è la matrice di dimensione della decomposizione che rappresenta la corrispondenza film-categorie. Così facendo, mappiamo le valutazioni correnti dell'utente dallo spazio originale a quello delle categorie. Calcoliamo la predizione della valutazione dell'utente su tutti i film come segue
4.2 Metodi Graph-based
I metodi graph-based sfruttano una idea simile a quella del collaborative filtering, ma utilizzano un grafo bipartito per immagazzinare le informazioni. Le raccomandazioni sono ottenute a partire dalla struttura della rete bipartita.
Sia un grafo bipartito, in cui di cardinalità ed di cardinalità sono due classi di identitià indicanti rispettivamente gli utenti e gli oggetti. Sia l'insieme degli archi E una funzione peso che rappresenta il grado di preferenza espresso dall'utente per un particolare oggetto. La utility matrix corrisponde alla matrice di adiacenza del grafo bipartito.
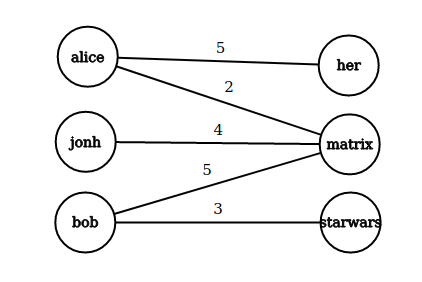
4.2.1 NBI - Network-based inference
La network-based inference è una tecnica sviluppata nel 2007 in cui si effettuano delle proiezioni sul grafo bipartito per ottenere informazioni. Dal grafo definito in precedenza è possibile estrarre due proiezioni: la proiezione rispetto agli utenti e quella rispetto agli oggetti. In una proiezione vi sono nodi appartenenti allo stesso insieme e due nodi sono connessi se e solo se sono connessi ad almeno un nodo in comune dell'altro insieme nel grafo di partenza.
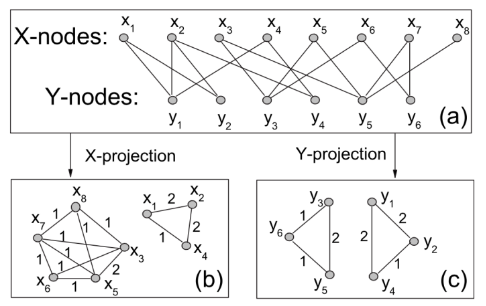
4.2.2 Idea dell'NBI
Sia il grafo bipartito definito in precedenza, definiamo una matrice di adiacenza dove Si esegue un processo di trasferimento delle risorse (resource transfer) tra i due insiemi della rete: all'inizio vengono trasferite delle risorse dall'insieme all'insieme e, successivamente, le risorse tornano da ad . La risorsa contenuta in un nodo viene trasferita equamente ai nodi adiacenti nell'altro insieme. Il processo a due fasi si ripete sino a convergenza. Questo metodo ci permette di definire una tecnica per il calcolo della matrice dei pesi di dimensione di una proiezione di rispetto all'insieme come segue: Quindi iteriamo per tutti gli item in e, se l'item è in comune tra i due utenti e , allora acquisisce valore inversamente proporzionale al grado dell'oggetto. La funzione è arbitraria e definisce il metodo graph-based utilizzato: Per ottenere le predizioni delle valutazioni, ovvero la matrice di raccomandazione , è sufficiente computare il prodotto riga-colonna tra la matrice dei pesi della proiezione del grafo bipartito (sugli utenti), che ha una dimensione , per la matrice di adiacenza del grafo bipartito , che ha una dimensione Il peso della proiezione corrisponde a quante risorse vengono trasferite dall'oggetto all'oggetto , o quanto piacerà l'oggetto ad un utente a cui piace l'oggetto .
Il NBI funziona su tutti i tipi di oggetti e risolve il problema della sparsità della utility matrix. Tuttavia persistono i problemi con i nuovi utenti o i nuovi item ed il metodo richiede importanti risorse computazionali.
4.3 Metodi ibridi
I metodi ibridi sfruttano una combinazione di diversi metodi di raccomandazione, risultando essere dei meta-sistemi. Supponiamo di avere due metodi ed che diano rispettivamente gli score e . Lo score di un modello ibrido può essere ottenuto come: I valori sono normalizzati per lo score massimo che il rispettivo metodo di raccomandazione ha ottenuto. Il modello è generalizzabile per l'utilizzo di sistemi di raccomandazione.
La valutazione dei risultati di un sistema di raccomandazione consiste spesso nel calcolare il root mean square error (RMSE) tra le valutazioni reali dell'utente e le predizioni del sistema. Una alternativa sta nell'interpretare il problema come un task di classificazione binaria, dove con 1 indichiamo una relazione tra utente e item e viceversa con 0. Di conseguenza sarà possibile calcolare metriche come la precision e la recall, o disegnare la curva ROC.
4.4 BellKor Recommender System
Il BellKor Recommender System è il sistema di raccomandazione che ha vinto il Netflix Prize. Combina tre fattori principali: gli effetti globali, la fattorizzazione ed il collaborative filtering.
4.4.1 Introduzione
Il collaborative filtering sfutta un criterio globale ed uno locale per effettuare la predizione finale, di fatto la raccomandazione dell'utente per l'item è ottenuta dalla seguente espressione: Dove con intendiamo la baseline per l'utente rispetto all'item e con intendiamo la similarità tra gli item e . Tale espressione vale nel caso degli item-item CF; nel caso degli user-user CF è sufficiente trasporre la matrice di utilità.
Il criterio globale nell'espressione consiste nell'utilizzo della baseline. La baseline è data dalla somma della media globale delle valutazioni , la deviazione delle valutazioni sul film rispetto alla media, la deviazione delle valutazioni dell'utente rispetto alla media. Quindi . Supponiamo che la media delle valutazioni sia stelle. Il film "Sesto senso" è valutato stelle sopra la media; l'utente Joe valuta i film sotto la media. La baseline estimation del rating di Joe per "sesto senso" è stelle. Tutte le informazioni utilizzate per il calcolo della baseline sono informazioni globali. Attraverso delle informazioni locali ottenute (ad esempio) attraverso il collaborative filtering, è possibile effettuare una predizione più precisa. L'espressione 10 fornisce tutto ciò che serve per il calcolo della predizione finale.
4.4.2 Parametri arbitrari
L'espressione 10 presenta un parametro totalmente arbitrario: la misura di similarità. La similarità influenza in maniera diretta il risultato del sistema, e quindi le dipendenze tra gli utenti (o tra gli item). È possibile sostituire la similarità con dei pesi calcolati attraverso un processo di training. Quindi riscriviamo l'espressione 10 Dove è un peso di interpolazione che modella l'interazione tra gli oggetti (o gli utenti), indipendente dall'utente. Assumiamo che:
4.4.3 Primo problema di ottimizzazione
La matrice di utilità è un dataset contenente dei dati reali, con cui possiamo confrontare i risultati del nostro sistema. Avendo le predizioni e sapendo calcolare la predizione , i pesi saranno l'incognita da trovare. A questo punto si utilizza un algoritmo di ottimizzazione per minimizzare il SSE (sum of square errors) calcolato sui dati di training (n.b. si utilizza il SSE anziché il RMSE poiché la derivata è più semplice).
La objective function da ottimizzare sarà la seguente: Un algoritmo di ottimizzazione possibile è la discesa del gradiente: sia il learning rate, aggiorniamo la nostra matrice di pesi come segue: e ripetiamo sino a convergenza. Anche se nell'espressione è presente il gradiente , in realtà si parla di matrice Jacobiana poiché presenta 2 dimensioni. Nel nostro caso avremo \forall i,x \and j \in N(i;x) , quindi vicino ad , altrimenti avremo:
4.4.4 Fattori latenti
Sia la matrice di utilità, effettuiamo la scomposizione SVD e riduciamo la dimensionalità a fattori latenti, otteniamo: Sia e , allora: Per stimare l'elemento della matrice è sufficiente effettuare il prodotto scalare tra la -esima riga di e la -esima colonna di (o analogamente, la -esima riga di )
4.4.5 Secondo problema di ottimizzazione
La SVD non è applicabile quando nella matrice vi sono elementi non definiti. Tuttavia è possibile ovviare al problema ricavando le matrici e attraverso i metodi di ottimizzazione. Consideriamo la seguente funzione obiettivo (sum of squared errors, SSE): Con indichiamo la -esima riga della matrice , con indichiamo la -esima riga della matrice . Il metodo non richiede che le due matrici siano ortonormali. Sia il numero di fattori latenti, si osserva empiricamente che l'ottimizzazione soffre di problemi di overfitting già per .
Introduciamo la regolarizzazione nella funzione obiettivo basandoci sull'idea che una maggiore quantità di valutazioni permette una predizione più accurata per un determinato utente. Geometricamente, si interpreta posizionando l'utente (vettore di valutazioni) lontano dal centro (quindi predizione più sicura) se il numero di valutazioni effettuate è alto. Nella pratica aggiungiamo il termine tra parentesi quadre: Dove sono parametri che permettono di eseguire un tuning sul peso della regolarizzazione. Anche questa volta è possibile utilizzare l'algoritmo di discesa del gradiente, iterando sino a convergenza ed aggiornando le matrici come segue Dove indica il gradiente (o più correttamente, la matrice jabobiana) della funzione obiettivo rispetto a : Ed analogo il calcolo di .
4.4.6 Stochastic Gradient Descent
Il calcolo del gradiente nell'algoritmo di discesa del gradiente è particolarmente oneroso, supponiamo di stare effettuando l'ottimizzazione per un regressore lineare : Supponiamo che la funzione obiettivo sia definita come segue Quindi lo step di aggiornamento dell'algoritmo di discesa del gradiente sarà: Ovvero per ogni coefficiente si calcola la derivata parziale della funzione obiettivo sull'intero training set. Se la dimensione del training set è particolarmente grande, i dati saranno molto probabilmente conservati in memoria secondaria. L'algoritmo risulta quindi molto pesante. Supponiamo di definire una funzione costo: Quindi riscriviamo la funzione costo come L'algoritmo di discesa del gradiente stocastico (Stochastic Gradient Descent, SGD) consiste in due step ripetuti in maniera iterativa:
- Permutare casualmente il training set
- Aggiornare i coefficienti come segue
Osserviamo che all'interno dello step di aggiornamento vi è la derivata parziale della funzione costo anziché della funzione obiettivo: questo implica che, ad ogni step, i pesi vengono aggiornati basandosi su una singola osservazione del training set e non su tutti i dati.
Lo stochastic gradient descent è molto più rapido dell'algoritmo di discesa del gradiente classico. Tuttavia, la convergenza ad un minimo locale della funzione obiettivo risulta essere più instabile e necessita di più step.
4.4.7 Costruzione del modello
È possibile combinare il predittore baseline con le interazioni utente-film ottenute attraverso la scomposizione in fattori latenti: Quindi minimizzare la funzione obettivo così proposta In questo caso sia le interazioni e che i bias e sono trattati come parametri da stimare e vengono aggiunti termini di regolarizzazione anche per i bias.
4.4.8 Bias temporali
Una ulteriore miglioria al modello consiste nel legare i bias e ed i fattori e al tempo, sotto la considerazione che la valutazione di un film tende ad essere stabile per i film vecchi ed instabile per i film nuovi.
La soluzione del team "BellKor's Pragmatic Chaos" vincitore del Netflix prize consiste nell'eseguire un blend lineare dei risultati di diversi tipi di predittori (approssimativamente 500) che sfruttano i concetti mostrati, ottenendo un miglioramento del 10.09%.