3. Dimensionality reduction
3.1 Introduzione
Molte fonti di dati possono essere viste come matrici di grandi dimensioni (web, social network [matrici di adiacenza], sistemi di raccomandazione [matrice di utilità]). Una matrice può essere riassunta da matrici di dimensione minore, con cui è più efficiente effettuare operazioni. Queste vengono ricavate con metodi di riduzione della dimensionalità. Si effettua riduzione della dimensionalità poiché alcune feature possono risultare irrilevanti, poiché vi è necessità di visualizzare i dati ad alta dimensionalità o poiché la dimensione intrinseca può essere inferiore al numero di feature.
3.1.1 Unsupervised feature selection
Nella feature selection supervisionata vengono selezionate le feature più interessanti rispetto ad una certa etichetta di classe. La dimensionality reduction può essere considerata una feature selection non supervisionata, poiché non si basa su etichette di classe, anche se le feature non vengono selezionate, bensì vengono definite in funzione di quelle originali.
3.1.2 Visualizzazione della riduzione
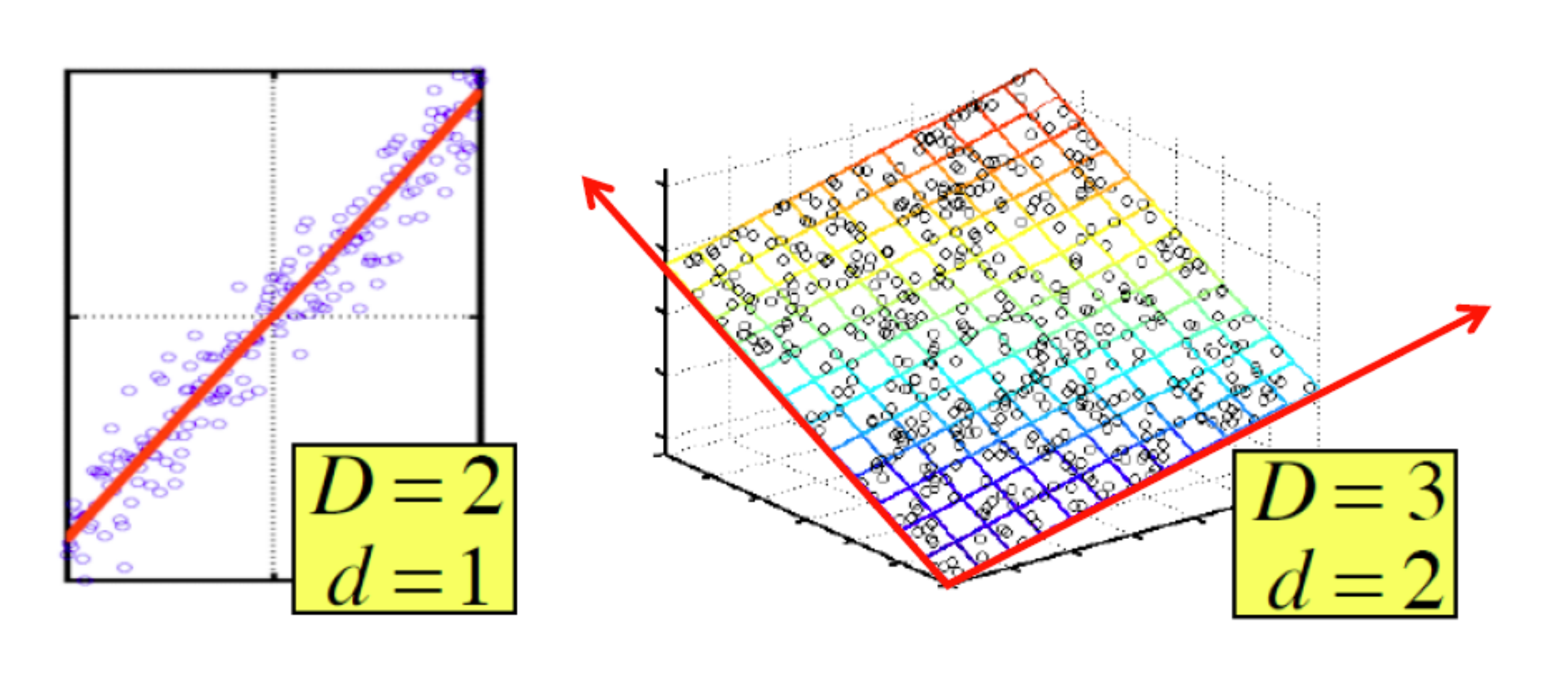
Supponiamo di avere dei punti distribuiti in uno spazio di dimensione . Può capitare che i punti cadano tutti vicini (o direttamente su) uno spazio a dimensione minore . In questo caso gli assi del sottospazio sono l’effettiva rappresentazione dei dati.
3.1.3 Richiami di algebra lineare
- Il rango di una matrice è un numero intero non negativo associato alla matrice . Ne indica il numero di righe (o colonne) linearmente indipendenti, ovvero non ricavabili attraverso combinazioni lineari di altre righe (o colonne).
- Si dice base di uno spazio vettoriale un insieme di vettori grazie ai quali possiamo ricostruire in modo unico tutti i vettori dello spazio mediante combinazioni lineari. Disponendo di una base di uno spazio vettoriale conosciamo quindi, automaticamente, l'intero spazio vettoriale.
- Si dicono coordinate (o componenti) di un vettore rispetto a una base gli scalari mediante cui il vettore si esprime come combinazione lineare dei vettori della base. Equivalentemente, fissata una base di uno spazio vettoriale, le coordinate di un vettore rispetto alla base scelta sono i coefficienti della combinazione lineare con cui si esprime il vettore in termini degli elementi della base.
- Sia una matrice quadrata. Sia una costante ed un vettore colonna non-zero con lo stesso numero di righe di . Diciamo che è un autovalore di ed è il suo corrispondente autovettore di se . La coppia prende il nome di autocoppia.
- Se è un autovettore di con autovalore e è una qualsiasi costante, allora anche è un autovettore di con lo stesso autovalore . Moltiplicare il vettore per una costante cambia il suo modulo ma non la sua direzione. Per evitare ambiguità assumeremo che ogni autovettore sia un vettore unitario (unit vector), ovvero di modulo 1.
- Sia una matrice quadrata con autovalori e corrispondenti autovettori . Se succede che allora chiameremo autovalore principale
3.1.4 Esempio pratico
Supponiamo di avere in input la seguente matrice A La matrice è bidimensionale, questo poiché è rappresentabile a partire dalla base Se si volesse ricostruire la quarta riga, sarebbe possibile sfruttare una combinazione lineare dei vettori (generatori) della base: Il rango della matrice è quindi l'effettiva dimensione (intrinseca) della matrice. Facciamo un altro esempio: La terza riga è ottenibile dalla differenza tra la prima e la seconda riga, per cui non è linearmente indipendente. Questo vuol dire che il rango è minore di 3. Determinato il rango , indichiamo una nuova base per la matrice: Ed otteniamo delle nuove coordinate per le tre righe: I vettori della base sono gli assi di rappresentazione dei dati, per cui possiamo rappresentare i dati come coefficienti di tali vettori e lavorare su dimensioni minori (2 anziché 3). Per ritornare da coordinate alla base di partenza è sufficiente calcolare la combinazione lineare .
3.1.5 Idea principale
L'obiettivo della dimensionality reduction è proprio quello di identificare gli assi dei dati. Molto spesso i dati non giacciono esattamente su una dimensione minore, per cui è necessario ammettere un margine di errore. Dato un insieme di punti in uno spazio -dimensionale, l'idea principale è quella di proiettare i dati in uno spazio con meno dimensioni preservando quanta più informazione possibile. Scegliamo la proiezione che minimizza il quadrato dell'errore quando ricostruiamo i dati originali.
3.2 Calcolo di autovalori ed autovettori
Nei richiami di algebra lineare abbiamo scritto che, per ogni autocoppia si ha che: Possiamo riscrivere l'equazione nel seguente modo:
Dove è una matrice identità delle stesse dimensioni di . Tale equazione in forma matriciale è rappresentabile come un sistema di equazioni lineari. La matrice corrisponde alla matrice la cui diagonale è ridotta di una fattore . Sia incognita, vogliamo trovare gli autovalori e gli autovettori della matrice .
Affinché si risolva l'equazione per un vettore , il determinante della matrice deve essere diverso da 0. Ciò è necessario poiché se allora per il teorema di Cramer il sistema lineare ammette una sola soluzione, che è banalmente (ma vogliamo una soluzione ). Sebbene il determinante di una matrice abbia termini, questo può essere calcolato in diversi modi in tempo , di seguito vedremo uno tra questi metodi.
3.2.1 Chiò pivotal condensation
Il metodo Chio pivotal condensation (condensazione pivotale) permette di calcolare il determinante di una matrice di dimensione andando a dividere il determinante di una nuova matrice di dimensione per il primo elemento della matrice elevato ad : Ipotesi necessaria è che la diagonale della matrice sia non nulla, quindi che . La matrice va costruita in funzione della matrice . Il generico elemento è ottenuto come segue: Si applica ricorsivamente il metodo alla matrice sino a che non si arriva ad una matrice il quale determinante è trattabile con metodi diretti.
3.2.2 Risolvere l'equazione
Dato che il determinante della matrice è un polinomio di grado dove è l'incognita, allora possiamo ottenere soluzioni, ovvero ottenere tutti ed gli autovalori della matrice . Un valore qualsiasi tra queste soluzioni risolverà l'equazione .
Per ogni autovalore trovato, è possibile ricavare il corrispondente autovettore risolvendo il sistema lineare di equazioni in incognite, ovvero le componenti dell'autovettore : Per semplicità imponiamo che ogni autovettore sia unitario, trovando così una sola soluzione. Facciamo un esempio banale: Quindi impostiamo l'equazione: Risolvendo la sottrazione all'interno delle parentesi otteniamo: Il determinante di questa matrice deve essere 0 poiché il sistema lineare abbia soluzioni: Risolvendo il polinomio di grado troviamo i due autovalori: Prendiamo la soluzione e sostituiamola all'equazione precedente: Ovvero: Risolviamo il sistema lineare ed otteniamo le componenti dell'autovettore associato all'autovalore . Ripetiamo il processo con l'autovalore .
3.2.3 Power iteration
Nella pratica, per matrici molto grandi, la soluzione precedente non è ammissibile. Studiamo un metodo alternativo computazionalmente meno oneroso, chiamato power iteration. Sia una matrice di dimensioni per la quale desideriamo calcolare le autocoppie.
Partiamo da un vettore generato casualmente di dimensione . Calcoliamo un nuovo vettore come segue: dove con intendiamo la norma di Frobenius: Osserviamo che, così facendo, il vettore sarà normalizzato ad 1. Procediamo iterativamente calcolando il generico vettore (per ) come segue: Fissato arbitrariamente un valore costante piccolo , l'iterazione si fermerà quando A questo punto, è approssimativamente l'autovettore principale di . Calcoliamo l'autovalore corrispondente attraverso la formula inversa: Utilizzando questo metodo ricaveremo la prima autocoppia principale (oss. è l'autovalore più grande). Per calcolare le rimanenti autocoppie è necessario enunciare il seguente teorema.
3.2.4 Generalizzazione della Power iteration
Sia una matrice simmetrica di dimensione con autovalori e autovettori. Supponiamo di aver calcolato l'autocoppia principale attraverso la power iteration. Per trovare la seconda autocoppia, creiamo una nuova matrice: Applicare la power iteration alla matrice restituirà l'autocoppia principale della matrice , ovvero l'autocoppia con autovalore più grande. Tale autocoppia corrisponde alla seconda autocoppia della matrice di partenza. Intuitivamente, quello che abbiamo fatto è stato rimuovere l'influenza dell'autovettore principale impostando il corrispondente autovalore principale a zero. Ciò viene giustificato dalle seguenti osservazioni:
- è ancora un autovettore di ed il suo autovalore corrispondente è .
- se è una autocoppia (non principale) di una matrice simmetrica allora sarà una autocoppia di .
È possibile trovare tutte le autocoppie ripetendo iterativamente il metodo:
Osservazione: Se gli autovettori non sono unitari, allora non sarà possibile calcolare la matrice B con l'espressione indicata, bensì si dovrà trovare un vettore tale che e quindi calcolare la matrice B come segue:
Il professore sostiene che l'autovettore ottenuto dalla power iteration su , che chiameremo non corrisponda all'autovettore su , che chiameremo , e che per calcolare l'autovettore originale bisogna applicare la seguente formula:
3.2.5 Implementazione
import numpy as np
import numpy.linalg as la
def powi (m, max_iter = 10 ** 3):
""" power iteration method """
_, n = m.shape
x = np.ones(n)
for _ in range(max_iter):
mx = np.dot(m, x)
fn = la.norm(mx, 'fro')
x = mx / fn
x = x.A[0]
ev = np.dot(np.dot(x.T, m), x).item(0)
return ev, x
def eigenpairs(m):
""" power iteration generalization for all eigenpairs """
_, n = m.shape
b = m
evecs = []
evals = []
for i in range(n):
lambdai, ei = powi(b)
evecs.append(ei)
evals.append(lambdai)
eim = np.matrix(ei)
b = b - lambdai * eim.T.dot(eim)
return evals, evecs
def main():
m = np.matrix([
[1,3,5],
[2,4,1],
[6,1,9],
])
eigen_values, eigen_vectors = eigenpairs(m)
for key, val in enumerate(eigen_values):
print(f'{key}) \t {val}')
3.2 PCA - Principal-Component Analysis
La Principal-Component Analysis (PCA) è una tecnica che prende un dataset relativo ad un insieme di tuple in uno spazio ad alta dimensione e trova le direzioni (assi) lungo il quale le tuple si allineano meglio. Trattiamo l'insieme di tuple come una matrice e troviamo gli autovettori di o . La matrice di questi autovettori può essere pensata come una rotazione rigida dello spazio ad alta dimensione.
3.2.1 Esempio illustrativo
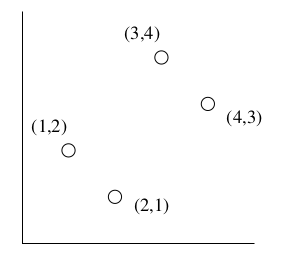
Rappresentiamo i dati nell'asse su una matrice : Calcoliamo il prodotto matriciale Troviamo gli autovalori come fatto nel paragrafo 3.2.2 Le cui soluzioni sono e . Troviamo gli autovettori risolvendo l'equazione lineare per ogni autovalore:
Costruiamo la matrice affiancando gli autovettori trovati e posizionando per primo l'autovettore principale: Ogni matrice con vettori ortonormali (vettori unitari ed ortogonali l'un l'altro) rappresenta una rotazione e/o riflessione degli assi di uno spazio Euclideo. Se moltiplichiamo la matrice per la matrice (rotazione) otteniamo: Nel caso in esempio, la matrice rappresenta una rotazione di in senso antiorario.
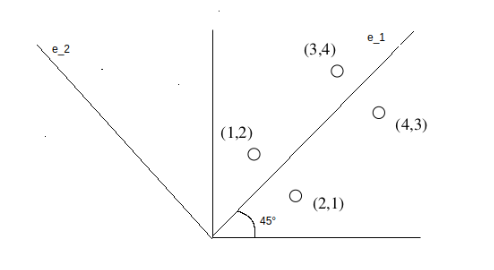
I punti mantengono le proporzioni dopo la rotazione, vediamolo graficamente:
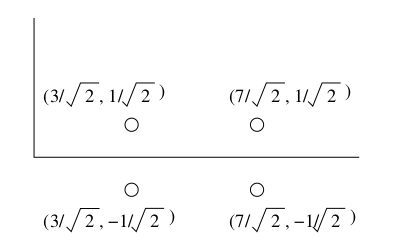
3.2.2 Ridurre la dimensionalità con PCA
corrisponde ai punti di trasformati in uno spazio di nuove coordinate. In questo spazio, il primo asse (quello che corrisponde al più grande autovalore) è il più significativo; formalmente, la varianza di un punto lungo questo asse è la più grande. Il secondo asse corrisponde al secondo autovalore, è il successivo secondo autovalore più significativo nello stesso senso. Questo pattern si presenta per ogni autocoppia. Per trasformare in uno spazio con meno dimensioni, basta preservare le dimensioni che usano gli autovettori associati ai più alti autovalori e cancellare gli altri. Sia la matrice formata dalle prime colonne di . Allora è una rappresentazione di a dimensioni.
Nel nostro esempio, rimuoviamo il secondo autovettore dalla matrice e ricalcoliamo il prodotto : Tale procedura ci garantisce un errore di approssimazione minimo.
3.2.3 Pseudocodice
PCA (M, k):
# Sia M una matrice di dati N x d, con ogni riga un vettore dei dati.
# Otteniamo la matrice di covarianza di M (sottraendo la media)
Sigma <- sottraiamo la media m da ogni vettore riga
autocoppie <- troviamo le autocoppie di Sigma
PC <- prendiamo i k autovettori con gli autovalori più grandi (principal components)
# PC sarà una matrice e gli autovettori saranno posizionati in colonna
return M * PC
3.3 SVD - Singular Value Decomposition
La Singular Value Decomposition (SVD) è una tecnica che permette di ottenere una rappresentazione a basse dimensioni di una matrice ad alte dimensioni e funziona per qualsiasi matrice. Maggiore è la riduzione, minore sarà l'accuratezza della approssimazione.
3.3.1 Definizione di SVD
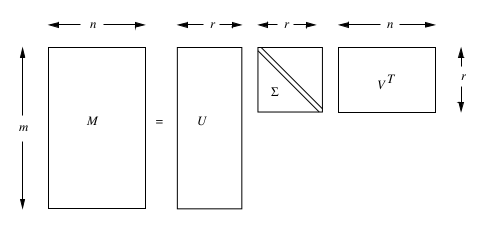
Sia una matrice , e sia il suo rango. Allora sarà possibile trovare le matrici , , e con le seguenti proprietà:
- è una column-orthonormal matrix, le cui colonne sono vettori unitari (vettori singolari di sinistra).
- è una column-orthonormal matrix, le cui colonne sono vettori unitari (vettori singolari di destra).
- è una matrice diagonale, i cui elementi (nella diagonale) sono chiamati valori singolari di .
Possiamo scrivere:
Per "column-orthonormal matrix" intendiamo una matrice le cui colonne sono vettori ortonormali, per cui il prodotto scalare tra due colonne distinte arbitrarie è 0. Si ha quindi che .
Nella decomposizione si farà utilizzo della trasposta della matrice , quindi . Essendo una column-orthonormal matrix e la sua trasposta, allora sarà una row-orthonormal matrix.
3.3.2 Interpretazione della SVD
Sia una matrice di dimensione contenente nelle righe gli utenti e nelle colonne i film valutati dagli utenti. Supponiamo che i primi 3 film nelle colonne siano fantascientifici, mentre gli ultimi due siano romantici: Le prime 4 righe sono linearmente indipendenti tra loro, così come le ultime 3 righe. Di fatto, il rango della matrice risulta essere . Supponiamo di aver già calcolato le tre matrici , e , scriviamo l'equazione della decomposizione: La chiave di lettura della decomposizione sta nell'interpretare le colonne delle matrici , e come concetti nascosti nella matrice di partenza . Nell'esempio i concetti sono molto chiari, le due colonne indicano i due generi principali: fantascientifico e romantico. La matrice connette gli utenti (righe di ) ai generi (concetti), mentre la matrice connette i film (colonne di ) ai concetti. Infine, la matrice indica la forza di ogni concetto.
L'esempio è particolarmente banale, nella pratica spesso la dimensione desiderata è inferiore al rango della matrice, per cui è necessario applicare alcune modifiche ed ottenere una decomposizione non esatta, ma che approssima al meglio la matrice . È necessario eliminare dalla decomposizione esatta quelle colonne di e che corrispondono ai valori singolari più piccoli (concetti meno affermati) così da ottenere una buona approssimazione.
Modifichiamo leggermente la matrice d'esempio e vediamo cosa succede: Il rango della matrice è adesso a causa delle modifiche: le ultime tre colonne non sono più tutte linearmente indipendenti. Tuttavia i concetti rimangono gli stessi. Vediamo cosa succede alla decomposizione: Il terzo valore singolare risulta molto piccolo rispetto ai primi due, poiché di fatto non è realmente incisivo (nel caso analizzato non indica nessun genere), vorremmo quindi eliminarlo.
3.3.3 Ridurre la dimensionalità con SVD
Supponiamo di voler rappresentare una matrice molto grande attraverso le sue componenti , e ottenute attraverso la SVD. Tuttavia, anche queste ultime risultano essere molto grandi da conservare. Il miglior modo per ridurre la dimensionalità delle tre matrici è azzerare il valore singolare di più piccolo e, di conseguenza, eliminare le corrispondenti colonne nelle matrici e .
Riprendiamo l'esempio precedente: supponiamo di voler passare da 3 dimensioni a 2. Il valore singolare più piccolo risulta essere 1.3, per cui lo azzeriamo e rimuovamo la terza colonna di e la terza riga di : La matrice risultante dal prodotto non coincide perfettamente con , ma ne è una buona approssimazione. Se calcoliamo l'RMSE (root mean square error) attraverso la norma di Frobenius sulla matrice otteniamo: Calcolando l'errore di approssimazione attraverso la metrica RMSE, è possibile dimostrare che ottenuta rimuovendo i valori singolari più piccoli, è la "best low rank approximation" di , ovvero l'approssimazione migliore ottenibile dalle 3 matrici , e .
3.3.4 Best low rank approximation theorem
Sia e dove è una matrice diagonale di dimensioni con: allora è la migliore apporssimazione di rango di , ovvero:
3.3.5 Legami con la decomposizione spettrale
La SVD è legata alla autodecomposizone o decomposizione spettrale di una matrice. Per il teorema spettrale abbiamo che: Dove (diagonale) ed contengono rispettivamente gli autovalori ed autovettori della matrice . Calcolando la SVD di abbiamo: Essendo una matrice diagonale, abbiamo che , continuiamo: In analogia alla decomposizione spettrale, possiamo dire che la matrice contiene gli autovalori della matrice , mentre la matrice ne contiene gli autovettori. Ripetendo lo stesso procedimento con otterremo: Per cui vi è un legame tra le due decomposizioni.
3.3.6 Azzerare i valori singolari piccoli funziona
Dato che , allora
Dato che è di dimensione e è di dimensione , allora il prodotto è una matrice.
Settare (dove è il valore singolare più piccolo) funziona perché essendo e vettori unitari, il prodotto con il valore scala i valori della matrice. Quindi eliminare il più piccolo introduce meno errore di approssimazione.
3.3.7 Quanti valori singolari mantenere
Una regola empirica per scegliere il numero di valori singolari da mantenere consiste nel mantenere almeno l'% (o il %) dell'energia. Ovvero, supponendo che il rango della matrice sia e di voler ridurre la dimensione della decomposizione, allora si sceglie tale che:
3.3.8 Complessità della decomposizione
I migliori algoritmi di calcolo della decomposizione SVD hanno una complessità temporale o , a seconda di quale è minore. Tuttavia vi è meno lavoro necessario se si vogliono ottenere solo i valori singolari (o i primi valori singolari), o se la matrice è sparsa.
3.3.9 Query utilizzando i concetti
Consideriamo la matrice dell'esempio precedente: Supponiamo che un nuovo utente abbia valutato un solo film, il primo, e che lo abbia valutato positivamente. Indichiamo il nuovo utente con il vettore riga . È possibile mappare le valutazioni del nuovo utente nello "spazio dei concetti" moltiplicandolo per la matrice della decomposizione: Dato che la prima componente del vettore risultante vale 2.32, mentre la seconda vale 0, possiamo derivarne che il nuovo utente è interessato a film di fantascienza (la prima categoria), mentre non è interessato a film d'amore. Il vettore risultante è una rappresentazione del vettore delle valutazioni nello spazio dei concetti. Possiamo mappare il vettore nuovamente nello spazio dei film moltiplicandolo per Questo ci suggerisce che il nuovo utente potrebbe essere interessato al secondo ed al terzo film. Un altro tipo di query consiste nel trovare utenti con interessi simili, mappando le loro valutazioni nello spazio dei concetti e calcolando la similarità tra i due vettori attraverso la distanza del coseno, che ci fornisce la differenza delle direzioni dei vettori.
Supponiamo che due vettori delle valutazioni mappati nello spazio dei concetti assumano valori e rispettivamente. I due vettori hanno la stessa direzione: entrambi si trovano sull'asse del concetto "fantascienza", per cui hanno gusti analoghi e la distanza del coseno è 0.
3.3.10 Conclusioni
La SVD è una buona decomposizione grazie al teorema sulla approssimazione low-rank ottimale. Tuttavia è di difficile interpretazione, poiché i vettori singolari specificano combinazioni lineari di colonne e righe di input, e le matrici ottenute non sono sparse, quindi mantenerle in memoria potrebbe essere problematico.
3.4 CUR decomposition
Spesso la matrice da decomporre è molto sparsa. Utilizzando la decomposizione SVD, le matrici , e sono dense. Idealmente si vuole che la decomposizione di una matrice sparsa sia altrettanto sparsa. La decomposizione CUR cerca di garantire questa proprietà. Questo metodo seleziona un insieme di colonne e un insieme di righe che giocano il ruolo di e nella SVD. La scelta delle righe e delle colonne è fatta in maniera casuale con una distribuzione che dipende dalla norma di Frobenius. Tra le matrici ed vi è una matrice quadrata costruita come pseudo-inversa dell'intersezione delle righe e delle colonne scelte.
3.4.1 Definizione di CUR
Sia una matrice di dimensione . Si scelgano concetti da utilizzare nella decomposizione. Una decomposizione di è formata da:
- Una matrice di dimensione formata da colonne prese casualmente da ;
- Una matrice di dimensione formata da righe prese casualmente da ;
- Una matrice di dimensione costruita da ed .
La matrice viene costruita mediante il seguente processo:
- Sia una matrice data dall'intersezione di ed , ovvero l'elemento corrisponde all'elemento di la cui colonna è la -esima colonna di e la cui riga è la -esima riga di ;
- Si effettua la decomposizione SVD su , quindi ;
- Si calcola la matrice pseudoinversa di Moore-Penrose della matrice diagonale , dove ogni elemento della diagonale non nullo si rimpiazza con l'elemento . Se l'elemento della diagonale è nullo, allora si lascia nullo.
- Si ottiene .
Perché la pseudoinversa funziona?
Scomponiamo la matrice utilizzano la SVD , allora deve accadere che . Essendo ed ortonormali, la loro trasposta corrisponderà all'inversa. Quindi scriviamo . Poiché la matrice è diagonale, allora , dove gli elementi in nulli vengono però mantenuti nulli (altrimenti si avrebbe una divisione per zero). Se è non singolare (determinante diverso da zero, di conseguenza esiste l'inversa ) allora la pseudo-inversa coincide con la vera inversa.
3.4.2 Teorema [Drineas et al.]
Sia la decomposizione di calcolata in tempo , allora si dimostra che: Con probabilità , selezionando:
Nella pratica basta selezionare righe e colonne, dove è il valore della "best k-rank approximation" nell'espressione 54, calcolata attraverso la decomposizione SVD azzerando gli valori singolari più piccoli.
Fissati e arbitrariamente, tale teorema ci fornisce il numero di righe e colonne da selezionare per dare un limite superiore all'errore di approssimazione con una certa probabilità.
3.4.3 Selezionare righe e colonne
Anche se la scelta delle righe e delle colonne è casuale, tale scelta deve essere direzionata in qualche modo tale da selezionare le righe e le colonne più importanti. La misura di importanza è data dal quadrato della norma di Frobenius: La probabilità di scegliere la -esima riga di è calcolata come segue: La probabilità di scegliere la -esima colonna di è calcolata come segue: Data la distribuzione di probabilità di righe e colonne, essendo che ogni selezione è indipendente dalle altre, notiamo che le righe con più alta probabilità possono essere selezionate più volte; torneremo più avanti su questo aspetto.
Una volta selezionata con probabilità assegnata una colonna dalla matrice , gli elementi di tale colonna vengono scalati (quindi divisi) di un fattore , la colonna scalata diventa poi una colonna della matrice . Allo stesso modo, selezionata una riga con probabilità assegnata dalla matrice , gli elementi di tale riga vengono scalati di un fatore , quindi la riga scalata diventa una riga della matrice .
3.4.4 Teorema sull'upper bound dell'approssimazione
Ipotizziamo di selezionare un numero analogo di righe e colonne attraverso le distribuzioni di probabilità assegnate dall'algoritmo CUR. Costruiamo quindi le matrici , ed , allora:
3.4.5 Righe e colonne duplicate
La decomposizione CUR è vantaggiosa perché facile da interpretare (i vettori della base sono righe e colonne della matrice) ed inoltre ha una base sparsa. Tuttavia, è possibile riscontrare duplicazioni su colonne e righe a causa della distribuzione di probabilità basata sulle norme: colonne e righe con norme alte verranno selezionate spesso.
Supponiamo che la matrice abbia colonne duplicate, possiamo ridurre queste colonne ad una sola colonna, diminuendo così il numero totale di colonne di . Allo stesso modo, se ha righe duplicate, allora è possibile ridurle ad una sola riga, diminuendo il numero di righe totale di . Tuttavia, tale riga o colonna rimanente dovrà essere scalata moltiplicando ad ogni elemento il valore .
Supponiamo che la matrice di dimensione diventi di dimensione dopo la rimozione dei duplicati. Supponiamo che la matrice di dimensione diventi di dimensione dopo la rimozione dei duplicati. Se il numero di duplicati è diverso in ed () allora la matrice di intersezione non sarà quadrata. Possiamo comunque calcolare la pseudoinversa dalla decomposizione di , dove è una matrice diagonale con alcune colonne o righe nulle (dipeso dalla dimensione maggiore). Si calcola la pseudoinversa canonicamente, e si esegue la trasposizione del risultato. Supponiamo: Allora:
3.4.6 Ottimizzazione dell'algoritmo
Si dimostra che per migliorare l'accuratezza della decomposizione (sulla base della norma di Frobenius), è sufficiente selezionare righe (o colonne) che siano ortogonali (quindi linearmente indipendenti) tra di loro.
3.5 NNMF - Non-negative matrix factorization
Sia una matrice di dimensione , in cui le colonne della matrice rappresentano le osservazioni di un insieme di dati, mentre le righe della matrice sono le corrispondenti feature. La tecnica NNMF ci permette di ottenere una decomposizione: Vogliamo ridurre il numero di feature da a . Le matrici avranno dimensione e . L'interpretazione di , chiamata anche matrice dizionario, consiste nel considerare ogni colonna come un vettore base, quindi un vettore che affiora frequentemente nelle osservazioni.
L'interpretazione di , chiamata anche matrice di attivazione o di espasione, consiste nel considerare ogni colonna come coordinate di una osservazione rispetto alla base . Quindi ci permette di ricostruire una approssimazione dell'osservazione originale attraverso una combinazione lineare delle basi in .
ed sono due matrici con elementi non negativi, ovvero . Il rango della fattorizzazione è scelto in modo tale che ed il prodotto è una rappresentazione compressa di . La non-negatività delle matrici ed induce sparsità.
3.5.1 Definizione di NNMF
Sia . Con indicheremo l'-esima colonna di Sia . Con indicheremo l'-esima colonna di In generale . Il vettore colonna è un vettore base.
Sia . Con indicheremo la -esima colonna di Il vettore colonna corrisponde all'osservazione rappresentata secondo la base formata dai vettori colonna della matrice .
Approssimeremo la feature -esima della -esima osservazione della matrice attraverso il prodotto scalare tra la riga -esima della matrice , che corrisponde all'-esima componente di ogni vettore base, per la -esima colonna della matrice , ovvero la -esima rappresentata attraverso la base .
3.5.2 Legame con Probabilistic Latent Semantic Analysis
Supponiamo che la matrice sia una matrice di co-occorrenza: sulle colonne sono disposti i documenti , sulle righe i termini . L'elemento indica quante volte il termine appare nel documento . Supponendo di introdurre il concetto di topic , quindi tematica trattata da un insieme di documenti, il modello PLSA asserisce che: Ovvero la probabilità di trovare il termine all'interno del documento . Tornando alla decomposizione NNMF, possiamo costruire un modello legato alla PLSA, assumendo che: e anche che quindi possiamo riscrivere il modello come Dove le basi in rappresentano concetti in grado di spiegare i dati analizzati utilizzando i relativi coefficienti in .
3.5.3 Funzione obiettivo
Le matrici e si ottengono minimizzando una certa funzione obiettivo, quindi: Due possibili funzioni obiettivo sono la distanza Euclidea O la divergenza di Kullback-Leibler (KL) Dove con indichiamo il valore stimato di dal prodotto .
3.5.4 Calcolo della NNMF
La NNMF di una matrice può essere calcolata iterando un processo sino a convergenza. Supponiamo di inizializzare le matrici ed in maniera casuale. Ricalcoliamo ad ogni iterazione le due matrici come segue: Dopodiché normalizziamo il risultato: Allo stesso modo calcoliamo la matrice Dopodiché normalizziamo il risultato: Le iterazioni convergono ad un massimo locale della seguente funzione obiettivo, che risulta essere una derivazione della divergenza di KL (in cui si rimuovono i termini costanti):
Assunzione di linearità Nelle decomposizioni affrontate si proiettano linearmente i punti da uno spazio ad un altro, preservando la distanza Euclidea. Altri metodi permettono di effettuare delle proiezioni non lineari (i.e. isomap), in cui i punti ricadono in una curva (manifold) a più bassa dimensione.