5. Finding Similar Items
Un problema noto è la ricerca di item simili: supponiamo di voler esaminare le pagine web per cercare casi di plagio. Un approccio naive consisterebbe nel calcolare la distanza di ogni coppia di pagine; tuttavia questo approccio risulta proibitivo nel caso di grandi dataset poiché quadratico.
5.1 Similarità tra insiemi
Supponiamo di rappresentare i documenti (i.e. pagine web) come insiemi. Un modo di calcolare la similarità tra due insiemi e è la similarità di Jaccard, definita come il rapporto tra la cardinalità dell'intersezione e dell'unione dei due insiemi:
Dare una lettura al sottocapitolo 3.1 di 'Mining of massive datasets' di Ullman et al.
5.2 Shingling
Il metodo più efficace per rappresentare insiemisticamente dei documenti, allo scopo di identificare documenti lessicalmente simili, consiste nel creare un insieme a partire dalle stringhe contenute nel testo. Due documenti simili avranno stringhe (es. parole o frasi) simili. Una semplice tecnica per ottenere un insieme da un documento testuale è lo shingling.
5.2.1 -Shingles
Un documento è una stringa di caratteri. Si definisca un -shingle di un documento come una qualsiasi sottostringa di lunghezza nel documento. Dopodiché vengono associati al documento un insieme di -shingles ed (opzionalmente) la loro frequenza assoluta.
5.2.2 Lunghezza dello shingle
Scegliendo un valore troppo piccolo, ci aspetteremo che quasi tutte le sequenze di caratteri siano presenti nella maggioranza dei documenti. Così facendo, ogni coppia di documenti avrebbe una similarità di Jaccard molto alta.
deve assumere un valore grande abbastanza, tale che la probabilità che un qualsiasi shingle appaia in un qualsiasi documento sia bassa.
Nel caso di un corpus di email, dovrebbe funzionare bene: supponendo che si incontrino solo caratteri alfabetici e spazi bianchi, allora avremo shingle. Essendo che una email è molto più corta del numero indicato, la probabilità che uno tra gli shingle appaia nel documento risulta essere bassa.
5.2.3 Hashing shingles
Sia l'insieme dei caratteri possibili in un documento e supponiamo, per semplicità, che essi siano 27. Per abbiamo possibili shingle. Ogni carattere occupa un byte, quindi un intero shingle occuperà 9 byte. Possiamo applicare una funzione di hashing che mappa ogni shingle in un numero tra e : Così facendo, ogni shingle sarà rappresentato da un intero a 4 byte. Lo spazio occupato sarà rispetto alla rappresentazione originale.
5.2.4 Costruire shingle da parole
Supponiamo di osservare una pagina web contenente un articolo con un certo topic. Come distinguiamo le stringhe provenienti dall'articolo dagli altri contenuti della pagina? Si osserva che gli articoli, come la maggior parte dei contenuti scritti in prosa, contengono molte stop words (congiunzioni, articoli, punteggiatura), ovvero parole poco significative nella distinzione del contenuto.
Tuttavia, si è dimostrato empiricamente che la tripla formata da una stop words e le due parole seguenti formano uno shingle molto efficace. In questo modo l'articolo contribuirà di più alla formazione degli shingle e la distinzione sarà basata su elementi provenienti dall'articolo piuttosto che dagli elementi circostanti della pagina web. La similarità di Jaccard sarà più alta per documenti con articoli simili rispetto a documenti con elementi circostanti all'articolo simili.
5.3 Min-Hashing
Gli shingle possibili sono moltissimi e, all'aumentare dei documenti, potrebbe essere impossibile tenere tutto in memoria principale. L'obiettivo principale è quello di sostituire grandi insiemi di shingle con una rappresentazione molto più piccola, chiamata signature (firma). La proprietà più importante che vogliamo rispettare è che, comparando le signature di due documenti, la similarità di Jaccard sia approssimativamente analoga a quella che si otterrebbe comparando i loro rispettivi insiemi di shingle.
5.3.1 Rappresentazione matriciale degli insiemi
Prima di tutto occorre costruire una characteristic matrix. In questa matrice, la -esima colonna rappresenta l'insieme di shingle estratto dal -esimo documento, mentre la -esima riga indica l'-esimo shingle tra tutti gli shingle possibili.
Esempio: supponiamo di avere 100 documenti, 27 caratteri possibili e . Per ogni documento estraiamo l'insieme di shingle. Nella matrice vi saranno 100 colonne (una per l'insieme di ogni documento) e righe (una per ogni possibile shingle).
L'elemento della matrice varrà 1 se lo shingle è contenuto nell'insieme degli shingle del documento , altrimenti varrà 0. Chiamiamo universal set l'insieme di tutti i possibili shingle.
5.3.2 Min-hashing
Le signatures degli insiemi che vogliamo ottenere sono composte dai risultati di centinaia di calcoli, chiamati minash della characteristic matrix. Supponiamo di avere la seguente matrice:
Per calcolare il minhash è necessario effettuare una permutazione delle righe, supponiamo che la prima permutazione sia e riscriviamo la matrice:
Dopodiché utilizziamo una funzione hash su ogni insieme (colonne). Tale funzione ritorna in output la prima riga dell'insieme che presenti un 1:
Quindi il minhash corrisponde a . Questo processo si ripete volte, dove è solitamente molto più piccolo della cardinalità dell'insieme universale. Una volta calcolato il minhash da una permutazione, esso va inserito come riga di una matrice, chiamata signature matrix:
Una volta ripetuto volte il processo con diverse permutazioni, la signature dell'insieme corrisponderà alla colonna -esima della signature matrix. Per semplicità, definiamo una funzione hash (notare l'assenza di permutazione al pedice) che rappresenti il processo di calcolo di una signature a partire da un insieme di shingle .
5.3.3 Min-hashing e Similarità di Jaccard
Vogliamo che valga la proprietà fondamentale per cui: Dove indica una particolare similarità tra signature che corrisponde alla frazione di minhash in cui esse coincidono:
Teorema 1
Si può dimostrare che:
Sia l'insieme di shingle e un elemento dell'insieme, allora:
Dove con indichiamo l'indice di nella permutazione . Possiamo affermare ciò poiché ogni elemento dell'insieme ha equa probabilità di essere primo nella permutazione .
Nota bene: la cardinalità corrisponde al numero di shingle contenuti nell'insieme, ovvero al numero di elementi nella colonna -esima posti ad 1.
Vogliamo studiare la probabilità che si verifichino i due eventi: Quindi che sia l'elemento di indice 1 nella permutazione in entrambi gli insiemi ed (ammesso che vi sia). La probabilità è sempre distribuita uniformemente, ma adesso è necessario considerare che tutti gli elementi dell'unione sono candidati ad essere primi, quindi:
P\left(\pi(y) = h_{\pi}(S_i) \and \pi(y) = h_{\pi}(S_j)\right) = \frac{1}{|S_i \cup S_j |}
Se volessimo trovare la probabilità che il primo elemento sia uguale in entrambi gli insiemi ed , è necessario considerare tutti gli elementi della loro intersezione come possibili candidati, dove ogni elemento ha probabilità uniforme, quindi: Il che dimostra la nostra tesi.
Teorema 2
Per semplicità, abbreviamo: Sia una soglia di similarità al di sopra della quale consideriamo due insiemi di shingle "altamente simili". Supponiamo che sia limitato inferiormente da una costante . Allora vale il seguente teorema:
Siano , , e , allora per ogni coppia di insiemi valgono le seguenti proprietà: Dove e sono parametri arbitrari; il teorema ci permette di limitare il numero di falsi positivi e falsi negativi (controllare l'errore). Dimostriamo la proprietà a) Scriviamo: Banalmente, poiché se l'evento accade con probabilità , allora l'evento complementare o contrario accade con probabilità .
Grazie al teorema precedente, possiamo asserire: Usiamo funzioni hash, quindi permutazioni e definiamo una variabile aleatoria come segue: Con Osserviamo che La variabile aleatoria è distribuita secondo una distribuzione binomiale, . Il valore atteso è noto e corrisponde a: Poiché la similarità originale corrisponde proprio alla similarità di Jaccard.
Sappiamo che la similarità tra signatures corrisponde al numero di volte in cui i minhash corrispondono (casi favorevoli) rispetto al numero di minhash totali, quindi scriviamo: Anche questa è una variabile aleatoria, il cui valore atteso corrisponde a: Quindi la similarità tra signatures è un estimatore corretto della similarità di Jaccard tra gli insiemi. Questo vuol dire che al crescere del numero di funzioni hash applicate, per la legge dei grandi numeri, l'estimatore converge al parametro stimato. Utilizziamo adesso un importante teorema, chiamato Chernoff Bound, che enuncia: Riscriviamo l'espressione dettata dal Chernoff Bound sostituendo i protagonisti e ricordandoci di aver considerato il complementare nell'espressione (17): Per ipotesi, sappiamo che: Quindi possiamo sostituire nella disequazione (26) con la similarità di Jaccard: Essendoci ricondotti al valore atteso di (vedasi espressione 22), è possibile applicare il Chernoff Bound: Fissati e , ricaviamo la quantità (funzioni hash necessarie ad ottenere un certo controllo dell'errore) risolvendo la disequazione: Quindi la proprietà è dimostrata.
5.3.4 Row hashing
Effettuare una permutazione è una operazione molto dispendiosa. Una ingegnerizzazione del min-hashing, chiamata row-hashing, permette di effettuare lo stesso procedimento rapidamente. Supponiamo di avere documenti e funzioni hash del tipo: Dove e sono due interi arbitrari, è un numero primo, è il numero di shingle e si ha che . Sappiamo a priori che la matrice delle signatures avrà dimensione . La procedure consiste nei seguenti passi:
- Inizializzare la matrice delle signatures ad .
- Per ogni riga (termine)
- Per ogni funzione hash
- Generare l'indice della riga nella permutazione data da
- Per ogni documento controllare se all'indice vi è un 1.
- Se è così, allora se l'elemento è maggiore di
- Se è così, allora se l'elemento è maggiore di
- Per ogni funzione hash
Vediamo un esempio: Supponiamo di avere funzioni hash definite come segue: Che generano le due permutazioni: Inizializziamo la matrice delle signatures: La riga della characteristic matrix ha indici nelle permutazioni generate dalle funzioni hash. I documenti ed hanno valore 1 nella prima riga, quindi possiamo aggiornare la matrice delle signatures come segue: La riga della characteristic matrix ha indici e solo il documento ha valore 1, aggiorniamo: La riga della characteristic matrix ha indici ; i documenti ed hanno valore 1, aggiorniamo i valori minori di quelli esistenti nella matrice delle signatures (ad esempio rimane lo stesso poiché e ): Allo stesso modo, per : E per : Abbiamo costruito la matrice delle signatures senza generare effettivamente le permutazioni delle righe di ogni colonna. Questa ingegnerizzazione rende il minhashing molto più rapido.
5.4 Locality Sensitive Hashing
Calcolare la similarità tra ogni coppia di documenti presenti nel database è un task dispendioso e l'approccio naive ha un tempo . Il Locality Sensitive Hashing permette di svolgere il task in tempo lineare controllando l'errore di approssimazione.
L'idea di base consiste nel generare uno sketch per ogni oggetto (nel nostro caso un documento) tale che:
- Sia molto più piccolo rispetto al suo numero originale di feature
- Trasformi la similarità tra due vettori di feature in una operazione di uguaglianza tra sketch
Tale metodologia è randomizzata e corretta con alta probabilità, quindi ammettiamo un certo numero (ragolabile) di falsi positivi e falsi negativi, ed inoltre è ottima in approcci distribuiti.
5.4.1 LSH e Distanza di Hamming
Per spiegare semplicemente il procedimento e le proprietà del LSH, prendiamo in considerazione la distanza di Hamming. Supponiamo di avere due vettori binari e con feature. La distanza di hamming è definita come
D(p,q) = \text{#bits where p and q differ}
Definiamo una funzione hash che prenda un insieme random di feature Ad esempio se , assumendo che allora la proiezione . Definiamo la similarità di Hamming come segue il rapporto tra le feature che combaciano nei due vettori binari e le feature totali: Scegliendo casualmente una posizione nei nostri vettori binari, la probabilità che il valore di e combaci nella posizione è data proprio dalla similarità: Dato che la funzione hash genera un insieme di posizioni random e indipendenti tra loro, la probabilità che e combacino in tutte e le posizioni corrisponde a: Aumentando
- Aumentano il numero di posizioni nell'insieme
- Aumenta la probabilità di trovare posizioni che differiscono nei due vettori binari
- Diminuisce la probabilità che i vettori binari combacino
- Diminuisce il numero di falsi positivi
5.4.2 Gestire i falsi negativi
Per ridurre i falsi negativi, l'idea implementata nel LSH sta nel ripetere volte le -proiezioni dei vettori e, ad ogni ripetizione, generare insiemi casuali differenti.
Abbiamo funzioni hash e definiamo la proiezione del vettore binario come Dichiariamo che è simile a , e scriviamo se almeno una proiezione combacia, ovvero se Più grande è , minori saranno i falsi negativi.
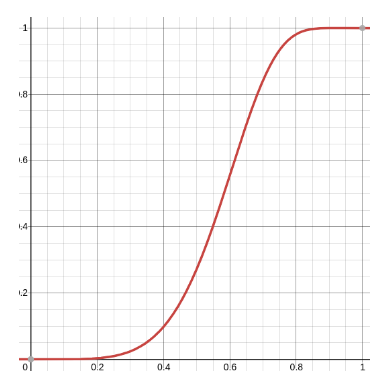
La probabilità che e non siano simili è data dalla probabilità che tutte le proiezioni non combacino Dato che le proiezioni sono indipendenti tra loro, è possibile scomporre la congiunzione degli eventi nel prodotto delle loro probabilità e, dato che la probabilità che esse non coincidano è la stessa qualunque sia la proiezione, possiamo scrivere: Infine scriviamo che è simile a con probabilità Se sull'asse delle indichiamo la similarità, la funzione ha il seguente andamento ad (per ed ):
Esempio
Supponiamo che ed e siano i due vettori Quindi procediamo a generare gli insiemi casuali:
- per abbiamo e , nessun match quindi proseguiamo;
- per abbiamo e , nessun match quindi proseguiamo;
- per abbiamo e , match! I vettori e sono simili.
5.4.3 LSH e min-hashing
Sia la matrice delle signatures di dimensione (m funzioni hash ed documenti) . Dividiamo le righe in bande (o gruppi contingui) ognuna formata da righe. Sia la soglia di similarità, allora utilizzando il LSH avremo la seguente situazione:
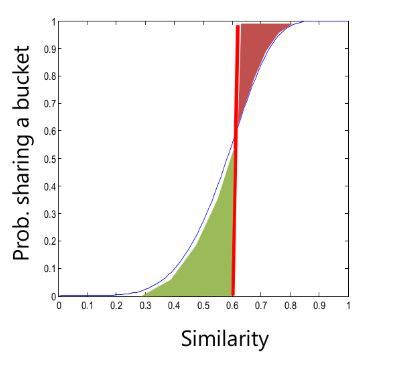
Se la linea rossa coincide con la soglia di similarità, l'area verde che la precede è la probabilità di incappare in un falso positivo, mentre l'area rossa che la succede è la probabilità di incappare in un falso negativo. Idealmente, vorremmo una funzione step che rifiuti tutto prima della soglia , dopodiché accetti tutto.
Esempio
Supponiamo che la soglia sia e che la similarità tra due insiemi di shingle ed sia Consideriamo e , quindi dividiamo la nostra matrice in 20 bande da 5 righe ciascuna. Per i teoremi precedenti, sappiamo che la probabilità che un minhash tra i due insiemi corrisponda all'interno della banda è: La probabilità che tutti i minhash corrispondano all'interno di una banda (ricordando ) è . Se consideriamo l'insieme degli hash in tutte le bande, avremo che: Quindi è simile ad con probabilità del %. Osserviamo come si comporta la funzione con coppie dissimili, quindi supponiamo: Avremo che Quindi è simile ad con probabilità del %, ovvero è poco probabile che essi risultino simili.
Caso ideale
Idealmente vorremmo che
5.4.4 Algoritmo LSH offline
- Per ogni feature vector , si calcola .
- Per ogni si crea un clustering (insieme di cluster differente per ogni banda) tale che due feature vector e si trovino nello stesso cluster se .
- Si crea un grafo non direzionato in cui i nodi e sono connessi se esiste un cluster che li contiene entrambi.
- Si calcolano le componenti connesse del grafo per identificare vettori simili.
Offline algorithm from Mining of massive datasets
If we have minhash signatures for the items, an effective way to choose the hashings is to divide the signature matrix into b bands consisting of r rows each. For each band, there is a hash function that takes vectors of r integers (the portion of one column within that band) and hashes them to some large number of buckets. We can use the same hash function for all the bands, but we use a separate bucket array for each band, so columns with the same vector in different bands will not hash to the same bucket.
5.4 Famiglie di funzioni LSH
L'esempio visto precedentemente è un esempio di famiglia di funzioni LSH, che possono essere combinate per distinguere coppie di punti distanti tra loro da coppie di punti vicini tra loro.
Una funzione locality sensitive è una funzione che soddisfa le seguenti 3 condizioni:
- Le coppie vicine devono essere candidate con probabilità maggiore rispetto alle coppie lontane.
- Deve assicurare l'indipendenza statistica per ogni operazione svolta.
- Deve essere efficiente:
- Il tempo necessario ad identificare le coppie candidate deve essere molto minore rispetto al tempo necessario per calcolare la distanza tra tutte le coppie.
- Si deve poter combinare per costruire delle funzioni più potenti che permettano di evitare falsi positivi e falsi negativi.
Una funzione locality sensitive prende in input 2 oggetti e decide se essi sono simili o meno, o perlomeno candidati ad essere simili (per poi computare la distanza successivamente su un insieme ristretto di oggetti) Una collezione di funzioni locality sensitive prende il nome di famiglia di funzioni locality sensitive. Diciamo che una famiglia è -sensitive se :
- Se la distanza allora la probabilità che è almeno
- Se la distanza allora la probabilità che è al più
5.4.1 Amplificare una famiglia locality sensitive
Costruzione in AND
Si costruisca una nuova famiglia dove ogni funzione è costruita da un insieme di cardinalità di funzioni della famiglia . Asseriamo che è costruita da tale che Questo processo è chiamato costruzione in AND e garantisce la costruzione di una famiglia -sensitive. In questo modo andiamo a ridurre entrambe le probabilità e, di conseguenza, il numero di falsi positivi.
Costruzione in OR
Si costruisca una nuova famiglia dove ogni funzione è costruita da un insieme di cardinalità di funzioni della famiglia . Asseriamo che è costruita da tale che Questo processo è chiamato costruzione in OR e garantisce la costruzione di una famiglia -sensitive. In questo modo andiamo ad aumentare entrambe le probabilità e, di conseguenza, riduciamo il numero di falsi negativi.
Le costruzioni in OR e in AND possono essere combinate in cascata per spingere la probabilità bassa a 0 e la probabilità alta a 1.
Esempio
Partiamo da una famiglia -sensitive ed eseguiamo una prima costruzione: Applicando in cascata prima una costruzione in AND con e dopodiché una costruzione in OR con . Le probabilità e della nuova famiglia saranno: Quindi sarà una famiglia -sensitive. Osserviamo che con questo approccio, la probabilità più bassa è stata schiacciata a 0.
Se costruiamo la famiglia in maniera inversa, quindi applicando in cascata prima l'OR e poi l'AND, avremo che le probabilità saranno: Quindi sarà una famiglia -sensitive. Invertendo il processo, la probabilità più alta è stata spinta verso 1.
Tentiamo adesso di costruire una famiglia applicando in cascata le seguenti costruzioni: Dove da ad applichiamo prima un AND (=4) e poi un OR () e da ad applichiamo prima un OR () e poi un AND (). Così facendo, le probabilità e saranno ricalcolate come segue: Plottando queste funzioni, avremo una curva molto più ripida che approssima meglio la step function ideale. Una soluzione del genere riduce molto bene sia il numero di falsi positivi che il numero di falsi negativi.
5.4.2 LSH su diverse distanze
Min hashing
La famiglia delle funzioni min-hash, assumendo che esse usino la distanza di Jaccard, sono Per ogni e tale che . Per le altre distanze non vi è alcuna garanzia che vi siano funzioni hash locality sensitive. Vedremo alcune delle più famose di seguito.
Distanza di Hamming
Siano e due vettori binari di dimensione , denotiamo con la loro distanza di Hamming. Definiamo una funzione che rappresenti l'-esimo elemento del vettore . Possiamo affermare che se e solo se e combaciano nell'elemento -esimo. La probabilità che combacino è Possiamo definire la famiglia di funzioni locality sensitive come una famiglia Con .
Distanza del coseno
La distanza del coseno ha senso in spazi aventi delle dimensioni (come gli spazi Euclidei o le versioni discrete degli spazi Euclidei). In tali spazi i punti hanno delle direzioni. La distanza del coseno tra due punti corrisponde all'angolo tra questi; tale angolo sarà definito tra 0° e 180° a prescindere da quante dimensioni sia costituito lo spazio. Possiamo calcolare la distanza del coseno calcolando prima il coseno dal rapporto tra il prodotto scalare tra i due vettori ed il prodotto tra le loro norme, poi applicando l'arcocoseno: È possibile dimostrare che la distanza del coseno è una misura di distanza. Se volessimo normalizzare il valore della distanza tra 0 ed 1, basterebbe dividere per Supponiamo di considerare due vettori ed . Tali vettori potrebbero trovarsi in uno spazio con molte dimensioni, Tuttavia insieme definiscono un piano e l'angolo tra loro e misurato sul tale piano:
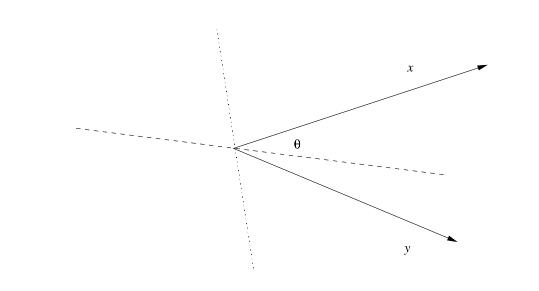
Selezionando in maniera casuale un iperpiano che passa dall'origine (asse tratteggiato in figura), esso intersecherà il piano formato da e . Per selezionare un iperpiano in maniera casuale, selezioniamo casualmente un vettore (asse punteggiato in figura), che sarà il suo vettore normale, dopodiché tutti i punti ortogonali a saranno punti appartenenti all'iperpiano.
Se effettuiamo il prodotto scalare tra ed i due vettori in figura, avremo prodotti con segni differenti: questo poiché essi capitano in lati opposti dell'iperpiano. Se l'iperpiano fosse stato l'asse punteggiato ed il suo vettore normale l'asse tratteggiato, allora i prodotti scalari avrebbero avuto lo stesso segno poiché dalla stessa parte dell'iperpiano.
In sintesi, preso un vettore random, definiamo la funzione hash Se il segno è positivo, i due vettori formeranno un angolo minore di , viceversa se il segno è negativo. La famiglia di funzioni locality sensitive per la distanza del coseno è formata da funzioni tale che: Si dimostra che la famiglia di funzioni appena definità è una famiglia
Al paragrafo 3.7.3 di Mining of massive datasets vi è un semplice trucco per la generazione degli sketch per vettori a cui deve essere applicata la distanza del coseno. Tale trucco consiste nel generare vettori casuali le cui componenti sono esclusivamente formate da +1 e -1, così che il prodotto scalare diventi la somma degli elementi a cui corrisponde un +1, a cui viene sottratta la somma degli elementi a cui corrisponde un -1.
Inoltre vi è un esempio che spiega come viene stimata la distanza del coseno. Supponiamo che gli sketch tra due vettori siano e , essendo che solo degl elementi combaciano, si stima come distanza un angolo di 120°.
Distanza Euclidea
Per semplicità, supponiamo di trovarci in uno spazio bidimensionale. Ogni funzione hash della famiglia è associata ad una retta casuale nello spazio. Fissata una costante dividiamo la retta in segmenti di lunghezza .
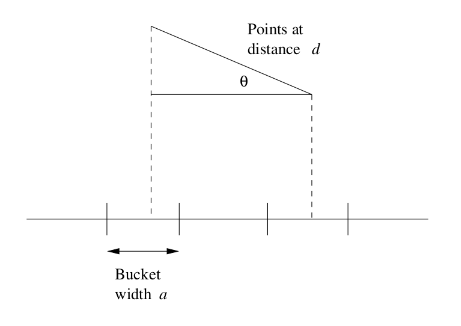
I segmenti sulla linea corrispondono ai b nerico punto è collocato nel bucket (segmento) in cui propria proiezione rispetto alla retta va a finire. Se la distanza tra due punti è molto più piccola rispetto alla costante , allora c'è una buona chance che i due punti vengano hashati nello stesso bucket, in tal caso, la funzione dichiara che i punti sono uguali.
a) Se , allora vi è almeno il 50% () di possibilità che essi ricadano nello stesso bucket. Se l'angolo formato dai due punti rispetto alla retta è grande, allora la probabilità che i punti ricadano nello stesso bucket è ancora maggiore: se rispetto ad , allora i due punti ricadranno per certo nello stesso bucket (la retta che passa tra i due punti è perpendicolare alla retta ).
b) Supponiamo che , quindi che i punti siano distanti tra loro: per cadere all'interno dello stesso bucket è necessario che . Basti guardare la figura, proiettando la distanza sulla retta essa è più grande di , quindi i punti staranno per certo in bucket differenti. Se allora la possibilità che i due punti ricadano nello stesso bucket è inferiore ad : infatti affinché il coseno sia inferiore ad (in modo da far rientrare le proiezioni nello stesso bucket) l'angolo deve stare tra 60° e 90°, ma l'angolo può assumere con probabilità uniforme un valore compreso tra 0° e 90°, quindi la probabilità che assuma quel range di valori è effettivamente .
La famiglia appena mostrata è una famiglia -sensitive. Il problema legato a tale famiglia sono le probabilità che non variano al variare del coefficiente . Tuttavia, è possibile effettuare delle costruzioni in AND ed in OR per manipolare tali probabilità.