6. Link analysis
Il web è un grafo orientato i cui nodi sono rappresentati dalle pagine web, mentre gli archi corrispondono ai link tra le pagine. Data una query di ricerca, il problema del web search consiste nel restituire dei siti web coerenti con la query, ma soprattutto autorevoli. Il primo approccio alla navigazione web fu' la web directory, ovvero un elenco di siti web curati manualmente e suddivisi in maniera gerarchica. Una web directory non è un motore di ricerca e risulta essere molto limitante. Il secondo tentativo fu' proprio il web search, che consiste in due problemi: il primo problema è il più semplice, consiste nel trovare un insieme di pagine che contengono parole in comune con la query, il secondo problema è più complesso e consiste nel ritornare solo pagine web autorevoli ed evitare lo spam.
6.1 PageRank
Il PageRank è un algoritmo di link analysis creato da Page, uno dei due fondatori di Google. Supponiamo di dare un valore di importanza iniziale a tutti i nodi, interpretiamo i link come dei "voti" e, se un nodo ha 10 link uscenti, allora dividerà la propria importanza equamente tra tutti e 10 i nodi. I link da pagine web importanti contano di più e tale concetto è implementabile attraverso la ricorsione.
6.1.1 Formulazione ricorsiva di base
Ogni voto di un link è proporzionale all'importanza della sua pagina sorgente. Se la pagina con importanza ha link uscenti, ogni link prende voti. L'importanza di è la somma dei voti dei suoi link entranti. Possiamo osservare che un voto da una pagina importante vale di più, e che una pagina è importante se viene puntata da altre pagine importanti. Definiamo il rank per la pagina attraverso una equazione di flusso Quindi il rank è dato dalla somma, per tutti i nodi che puntano a , del voto del nodo , che è calcolato dividendo la sua importanza per il suo grado uscente. Vediamo un grafo d'esempio
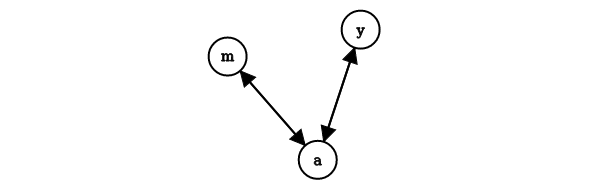
In questo caso avremo che Questo è un sistema di 3 equazioni in 3 incognite con infinite soluzioni (equivalenti a meno di un fattore di scala). Un vincolo addizionale rende la soluzione unica: Da cui otteniamo che , ed . Con un risolutore di equazioni lineari è possibile trovare le soluzioni per piccoli grafi. Tuttavia, il grafo del web è massivo e necessita di una nuova formulazione.
6.1.2 Formulazione matriciale
Supponiamo di avere una matrice di adiacenza per il grafo del web e consideriamo la formulazione stocastica di tale matrice, ovvero: La riga -esima della matrice indica gli archi entranti ad . L'elemento vale se il nodo , supponendo abbia archi uscenti, ha un arco uscente che punta ad . Strutturando così la matrice avremo che la somma delle colonne sarà pari ad 1.
6.1.3 Vettore dei rank
Introduciamo un vettore , chiamato vettore dei rank, tale che per ogni componente , indichi il rank del nodo -esimo. Imponiamo come vincolo che la somma delle componenti sia 1, quindi . Possiamo riscrivere l'equazione di flusso (1) nel seguente modo: Nel prodotto riga colonna, la componente di verrà calcolata attraverso la somma dei rank dei nodi che puntano a (informazione contenuta nel vettore ), diviso per il loro grado uscente (informazione contenuta nella matrice ). Osserviamo che è un autovettore della matrice stocastica , con corrispondente autovalore . Possiamo dire inoltre che 1 è l'autovalore più grande, essendo una matrice stocastica sulle colonne (con entry non-negative). A questo punto è possibile ottenere attraverso il metodo Power iteration:
- Supponiamo di avere pagine web, inizializziamo ;
- Iteriamo lo step di aggiornamento
- Fermiamo l'iterazione quando
Calcoliamo il rank vector per l'esempio precedente (2). La matrice stocastica sarà Inizializziamo casualmente Quindi computiamo E continuiamo fino a convergenza.
6.1.4 Random walk surfer
Immaginiamo un random web surfer, ovvero qualcuno che navighi tra le pagine del web attraverso i link. Se al tempo il surfer è sulla pagina , allora al tempo il surfer seguirà uno tra i link uscenti di in maniera casuale ed uniforme. Il processo è ripetuto all'infinito.
Sia il vettore la cui -esima componente indica la probabilità che il surfer sia alla pagina a tempo . Allora è la distribuzione di probabilità sulle pagine del web. Possiamo descrivere il cammino del random surfer come un processo markoviano, per cui avremo Supponiamo che si raggiunga uno stato per cui Allora sarà la distribuzione stazionaria del random walk. Il nostro vettore soddisfa , quindi è la distribuzione stazionaria della random walk eseguita dal random web surfer. Dallo studio delle catene di Markov si evince che per grafi che soddisfano certe condizioni, la distribuzione stazionaria è unica e sarà raggiunta a prescindere da quali saranno le probabilità iniziali a tempo .
6.1.5 Oscillazioni, dead-end e spider-trap
In alcuni casi la computazione del page rank potrebbe non convergere. Vediamo un primo caso in cui si presenta un ciclo nella rete ed il risultato oscilla all'infinito:

Supponiamo di inizializzare , allora avremo ovvero una soluzione che oscilla all'infinito e non converge mai. Osserviamo un altro caso:

Il nodo è un dead-end, ovvero un nodo che non ha link uscenti. Se il random walk si trova sul nodo , allora vi rimane per sempre. I nodi dead-end causano la perdita dell'importanza, fenomeno denominato leak out. Osserviamo un ultimo caso:
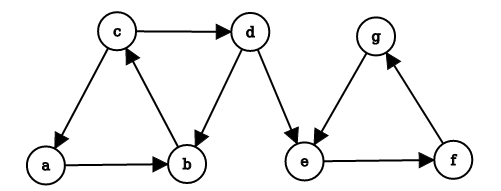
Quando il random walker entrerà nel nodo , navigherà per sempre all'interno del gruppo e non uscirà mai. Questa situazione è chiamata spider-trap, poiché il random walker è intrappolato all'interno del gruppo di nodi. La spider-trap assorbirà tutta l'importanza (esempio p.174, Mining of massive datasets).
6.1.6 Teleport
La soluzione di Google ai problemi elencati precedentemente prende il nome di teleport. Ad ogni step, il random surfer ha due opzioni:
- Con probabilità segue un link in modo random
- Con probabilità salta ad un nodo random
Valori comuni per sono nel range . Il surfer sarà teletrasportato fuori dalla spider-trap in un numero ragionevole di time-step. Questo approccio non solo risolve i problemi, ma riflette la realtà dei fatti: un navigatore del web può utilizzare la barra dell'URL per direzionarsi ad un'altra pagina anziché continuare a seguire i link. A questo punto illustriamo l'equazione di flusso del PageRank [Brin-Page, '98] In questa formulazione non ha dead-end. È possibile pre-processare la matrice e rimuovere tutti i dead-end, oppure eseguire il teleport con probabilità 1 per uscire dal dead-end. Possiamo introdurre la matrice di Google formulata attraverso la precedente equazione, come: Ancora una volta è possibile applicare la power iteration per trovare il vettore dei rank , infatti
6.1.7 Ottenere l'equazione
Aggiungere il teleport al PageRank equivale a tassare ogni pagina di una frazione del suo score e ridistribuirlo uniformemente tra i nodi. Partendo dall'equazione E sapendo che è definita come nella equazione (12), possiamo scrivere che: Ma ricordando il vincolo possiamo scrivere Che equivale a scrivere
6.1.8 Algoritmo completo
Presi in input
- Il grafo diretto (con spider-trap e dead-end)
- Il parametro
L'algoritmo consiste nei seguenti passi:
- Si inizializza
- Sinché si ripete:
- Per ogni :
- se
- se
- Per ogni :
- dove
- Si assegna
- Per ogni :
- Si ritorna in output
Si noti che nell'algoritmo non si aggiunge ad direttamente un valore , ma si passa per una variabile intermedia . Ciò è fatto per evitare di normalizzare il vettore alla fine di ogni iterazione (per rispettare il vincolo tale che la somma delle componenti sia 1). Una volta aggiornato si sommano in tutte le sue componenti e si ottiene un valore . Vogliamo che la somma delle componenti sia 1, quindi distribuiamo il residuo uniformemente alle componenti. Il passo è analogo ad aggiornare il vettore con la regola del PageRank e normalizzare alla fine.
6.2 Ingegnerizzazioni del PageRank
Il passo chiave del PageRank è la moltiplicazione tra la matrice ed il vettore . L'algoritmo è semplice se si ha memoria principale a sufficienza. Supponiamo che il numero di pagine sia miliardo e che ogni entry occupi byte. I vettori ed occupano circa GB (2 miliardi di entries). La matrice ha entries, ovvero , che è un numero davvero grande.
6.2.1 Matrice di adiacenza sparsa
La matrice di adiacenza del grafo del web è molto sparsa, risulta quindi insensato scegliere (nella pratica) una rappresentazione come quella matriciale. È possibile codificare la matrice utilizzando solo le entry diverse da 0, con uno spazio occupato proporzionale al numero di link (es. con le liste di adiacenza).
6.2.1 Operazioni in memoria secondaria
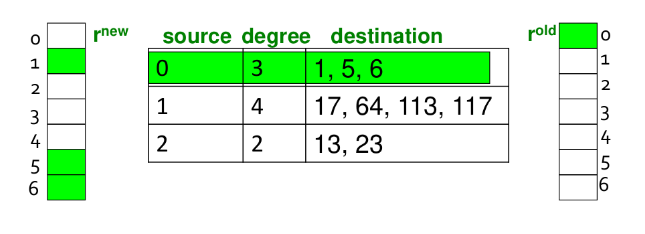
Supponiamo che solo stia in memoria, mentre la matrice e siano conservati sul disco. Possiamo modificare l'algoritmo PageRank ed operare nel seguente modo:
- Inizializziamo tutte le entry di a
- Per ogni nodo :
- Si legge sul disco ( = outlink)
- Per ogni si aggiorna :
Ad ogni iterazione bisogna leggere ed dal disco e scrivere su disco, quindi il costo per iterazione del power method è .
6.2.2 Aggiornamento block-based
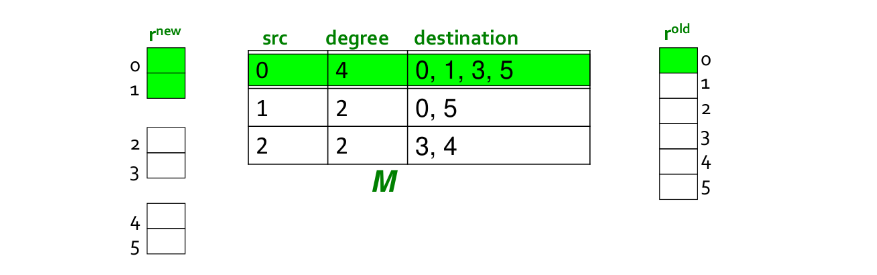
Se lo spazio in memoria principale non fosse sufficiente ad ospiare , si potrebbe pensare di suddividere il vettore in blocchi che entrano in memoria. In tal caso si scansionerebbero ed una volta per ogni blocco, con un costo per iterazione di power method pari a .
Tuttavia possiamo ottimizzare l'algoritmo escludendo del lavoro inutile: ipotizziamo di avere in memoria il blocco di di indici . Iniziando per , andiamo a recuperare la lista di adiacenza e controlliamo i suoi outlink. Supponiamo che gli outlink di 0 siano , allora anziché aggiornare tutti gli outlink di 0, si aggiornano solo quelli contenuti nel blocco, in questo caso .
6.2.3 Block-Stripe Update Algorithm
Nel paragrafo precedente abbiamo un algoritmo che, per ogni iterazione, legge la matrice (che è molto più grande di ) volte. Per evitare questa lettura continua è possibile suddividere in striscie: ogni striscia conterrà solo i nodi destinazione del corrispondente blocco in . Avremo un overhead per striscia trascurabile ed un costo per iterazione di power metodo di ( indica l'overhead).
6.3 Topic-Specific PageRank
Supponiamo di immetere la query "trojan" su un motore di ricerca: la ricerca potrebbe essere legata alla sicurezza informatica, alla storia (cavallo di Troia) etc... per cui è necessario un processo di disambiguazione. L'idea del topic-specific PageRank consiste nell'aggiungere un bias alla random walk: quando il walker si teletrasporta, sceglie una pagina da un insieme , chiamato insieme di teletrasporto (teleport set). contiene solo pagine che sono rilevanti per il particolare topic (ottenibile da strutture come le Open Directory). Per ogni teleport set , otteniamo un vettore specifico che ci indica l'importanza delle pagina per il particolare topic.
6.3.1 Formulazione matriciale
Per far si che questo funzioni è necessario aggiornare il teletrasporto nella formulazione del PageRank e definire la matrice per casi: La matrice è ancora stocastica. Vengono pesate allo stesso modo tutte le pagine all'interno del teleport set . È possibile anche assegnare pesi differenti alle pagine con soluzioni più sofisticate.
Essendovi un teleport set per ogni topic, avremo più vettori di rank calcolati considerando di volta in volta un teleport set differente. Così facendo si ottengono dei vettori di importanza delle pagine differenti per ogni topic.
6.4 SimRank
L'algoritmo SimRank serve a misurare la similarità (o prossimità) dei nodi di un grafo. Supponiamo di trovarci in un grafo -partito con tipi di nodi. Supponiamo di voler misurare il SimRank score per un nodo , l'idea dietro l'algoritmo consiste in una random walk partendo da con un teleport set contenente solo il nodo analizzato. Questo particolare tipo di random walk prende il nome di random walk with restart, poiché il teleport riporta sempre al punto di partenza.
6.4.1 Esempio
Consideriamo un grafo tripartito con tre tipi di nodi: Autori, Conferenze e Tag. Ogni autore è collegato a diverse conferenze ed ogni conferenza è collegata a diversi Tag. Siamo interessati a calcolare la similarità tra gli autori del grafo. Si procede calcolando il SimRank per ogni autore, tale score conterrà dei valori interpretabili come la similarità con tutti i nodi del grafo.
6.5 Web spam
Si considera spamming qualsiasi azione deliberata per far avanzare una pagina web nelle posizioni dei risultati di un search engine, con un valore molto più alto di quello reale. Nel caso di studio, lo spam equivale ad una pagina web emersa come risultato dello spamming. Una più ampia definizione si trova nel contesto della Search Engine Optimization (SEO).
I primi Search Engine non riuscivano a bloccare lo spam poiché si basavano esclusivamente sul contenuto testuale delle pagine in relazione alla query di ricerca. Supponiamo che lo spammer abbia un negozio di magliette e che la parola "tennis" sia il trend del momento. Allora basterà aggiungere alla propria pagina e-commerce tante volte la parola "tennis" e nascondere il testo in qualche modo. Se un utente avesse cercato "tennis", lo shop di magliette sarebbe stato ben posizionato nei risultati del motore di ricerca. Google fornì una soluzione al problema basandosi su un concetto semplice: "Credere in quello che dicono le persone di te e non a quello che dici tu di te stesso". Quindi se le pagine che puntavano con dei link allo shop di magliette non parlavano di tennis, allora molto probabilmente lo shop di magliette non parla di tennis, quindi viene penalizzato nella ricerca.
6.5.1 Spam farm
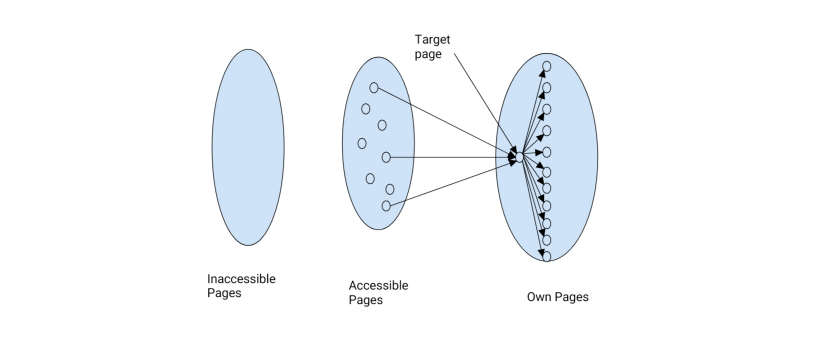
Quando Google divenne il motore di ricerca dominante, gli spammer si misero alla prova cercando di eludere il sistema: vennero fuori le spam farm. Categorizziamo le pagine in base alla accessibilità dello spammer:
- Le pagine inaccessibili sono pagine a cui lo spammer non ha accesso
- Le pagine accessibili sono pagine in cui lo spammer può inserire contenuto limitatamente
- Le pagine possedute dallo spammer sono le pagine che si vuole far emergere
La spam farm consiste nell'andare a creare il maggior numero di link che vanno da pagine accessibili alle pagine possedute, di cui si vuole migliorare il ranking. Esempi di pagine accessibili sono i blog o i social network, dove è possibile inserire del contenuto.
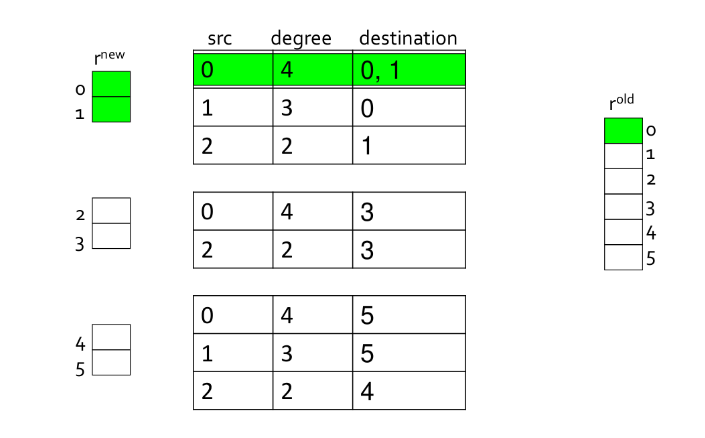
6.5.2 Spam gain
Supponiamo di voler calcolare lo score del PageRank di una pagina su cui agisce una spam farm. Sia il contributo (incognito) di PageRank dato a dalle pagine accessibili. Supponiamo che sia collegato ad pagine possedute e ogni pagina posseduta sia collegata solamente a . Sia il PageRank di , allora possiamo dire che cede ad ognuna delle M pagine accessibili uno score pari a
Dato che le pagine possedute sono collegate solo a , restituiranno questo score, tuttavia ridotto a a causa del contributo del teletrasporto. Quindi sommando questi contributi ad e considerando il teletrasporto, abbiamo che è definito come segue
Se risolviamo l'equazione per
È possibile omettere dall'equazione il termine poiché prossimo a 0, quindi riscriviamo
Essendo al numeratore, aumentando il numero di pagine possedute è possibile aumentare il rank della pagina .
Google Bombing
Un'altro modo di ingannare un search engine è il bombing. Consiste nel far puntare le pagine proprie e quelle accessibili, che trattino di uno specifico topic , verso una pagina web non accessibile, aumentando il punteggio di quest'ultima nei confronti del topic . Un tipico esempio è il bombing al presidente Bush, associato a topic denigratori.
6.6 TrustRank
Un approccio naive per combattere il link spam consiste nell'inserire in una blacklist tutte le strutture che sembrino simili a delle spam farm. Tuttavia, è stato sviluppato un algoritmo che permette di calcolare un punteggio legato alla affidabilità della fonte, chiamato TrustRank: consiste in un topic-specific PageRank, con un teleport set di pagine trusted (affidabili), come i siti governativi (.gov), i siti educazionali (.edu), etc.
6.6.1 Implementazione del TrustRank
Il principio di base è quello di approssimare l'isolamento: è raro che una pagina "buona" punti ad una pagina "cattiva" (spam). Si parte da un insieme di pagine web, chiamato seed set, curato manualmente. Risulta particolarmente dispendioso creare un seed set, per cui è un insieme molto ridotto.
L'insieme di teletrasporto corrisponde al seed set. Si inizializza ad 1 il valore di trust di ogni pagina all'interno di , mentre si inizializza a 0 la trust delle pagine esterne ad . Il TrustRank propaga la trust dalle pagine in alle pagine esterne, come succede nel PageRank. Sia l'insieme di out-link della pagina , allora per ogni pagina , riceverà da un contributo di trust pari a Dove ci ricorda che una parte di trust è riservata al meccansismo di teleport a delle pagine trusted. La trust è additiva, quindi la trust della pagina è la somma di tutte le trust conferite a delle pagine che la linkano. Entro un fattore di scala, il TrustRank corrisponde al PageRank, con le pagine trust come teleport set. Alcune osservazioni:
- Attenuazione della trust: la trust decresce con la distanza nel grafo
- Trust splitting: più sono gli outlink, minore sarà il contributo di trust trasferito.
6.6.2 Costruzione del Seed Set
Il seed set è manualmente curato e deve essere più piccolo possibile. Allo stesso tempo esso deve assicurare che ogni pagina buona ottenga un trust rank sopra la soglia: le pagine buone devono essere raggiungibili dal seed seed con un cammino relativamente corto. Da queste osservazioni in contrasto possiamo comprendere quanto sia complesso prelevare un buon seed set. Le due principali tecniche sono:
- Eseguire un PageRank e selezionare le pagine con rank più alto (difficilmente di spam);
- Utilizzare delle pagine la cui appartenenza è controllata (.edu, .gov, .mil)
6.7 HITS: Hub and Authorities
HITS (Hyperlink-Induced Topic Search) è un algoritmo, sviluppato da Jon Kleinberg, di valutazione delle pagine web in funzione dei link. Pubblicato nello stesso periodo del PageRank, ha avuto meno successo ma introduce comunque un'idea interessante. Supponiamo di voler trovare un buon quotidiano: anziché trovare i quotidiani migliori da soli, ci rivolgiamo ad un esperto che sappia consigliarci, linkando in modo coordinato a buoni quotidiani. Ancora una volta si presenta il concetto di link come voti. Definiamo due score:
- Qualità di esperto (hub): voti totali ricevuti dalle authority che puntano a loro
- Qualità sui contenuti (authority): voti totali ricevuti dagli esperti
Ogni pagina avrà entrambi gli score, ed in base a questi (le pagine interessanti) si divideranno in due classi:
- Le Authority sono pagine che contengono informazioni utili (Home di un quotidiano)
- Gli Hub sono pagine che si collegano alle authority (Elenchi di quotidiani)
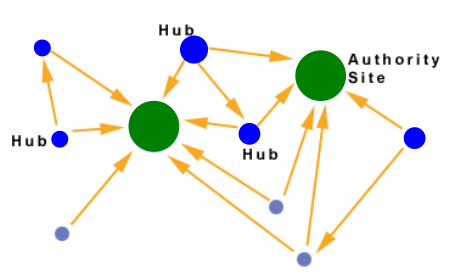
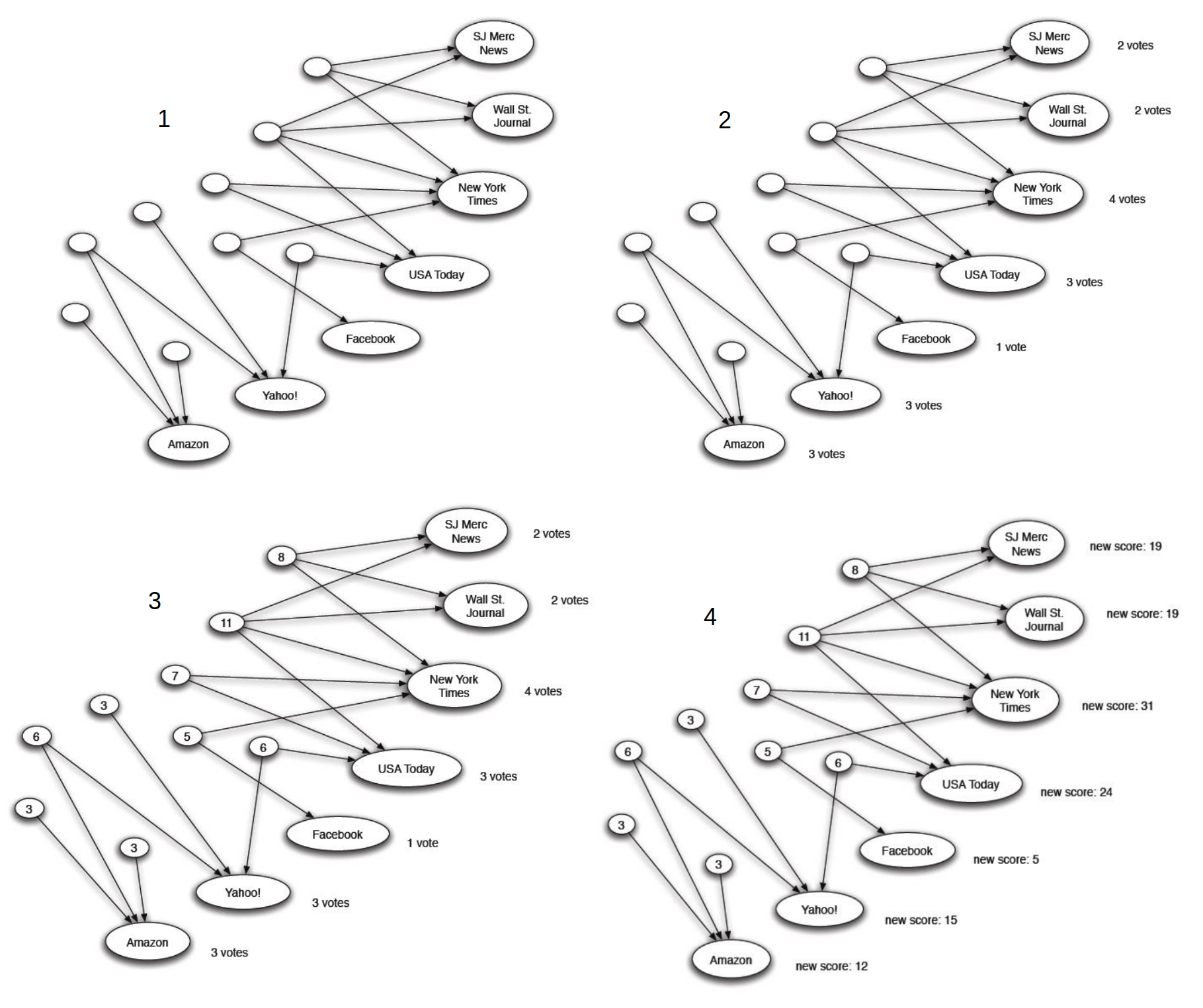
L'intuizione è che un buon hub linka diverse buone authority, ed una buona authority è linkata da diversi buoni hub. Vediamo una approssimazione intuitiva della procedura:
- Si inizializza lo score di hub ad 1 per ogni nodo
- Si calcola l'autority di ogni nodo sommando l'hub di ogni suo link entrante
- Si calcola l'hub di ogni nodo sommando l'authority di ogni suo link uscente
- Si riparte dal secondo step sino ad una stabilizzazione (con dovuti accorgimenti)
6.7.1 Algoritmo
Ogni pagina ha un authority score ed un hub score . Al tempo 0 si inizializzano gli score per ogni nodo all'interno del grafo:
Dove è il numero di nodi. Si itera la seguente procedura sino alla convergenza:
- Per ogni nodo al tempo si calcola l'autority:
- Per ogni nodo al tempo si calcola l'hub:
- Si normalizzano i risultati imponendo
L'algoritmo converge ad un singolo punto stabile.
6.7.2 Algoritmo in notazione vettoriale
Indichiamo con il vettore di tutti gli autorithy score, e con il vettore di tutti gli hub score. Sia la matrice di adiacenza (ricordando che se , 0 altrimenti), allora possiamo scrivere che Ne segue che . In modo simile possiamo scrivere che Ne segue che . Quindi riscriviamo l'algoritmo in notazione vettoriale, inizializzando:
E iterando sino a convergenza
- Si normalizzano ed
I criteri di convergenza, considerando un valore piccolo, sono:
Possiamo incorporare la normalizzazione nei passi di aggiornamento andando a definire
E modificando gli step di aggiornamento come segue:
È possibile effettuare delle sostituzioni:
Sotto una assunzione ragionevole di , l'algoritmo HITS converge a dei vettori e tali che
- è l'autovettore principale di
- è l'autovettore principale di
- (supp.) è l'autovalore